8 Min Read

The story
Due to the high rate of inflation, buying monthly groceries has become a sport. One has to go to the ends of the world in order to good prices on the items they need. When creating a monthly grocery list one has to go through countless catalogues or websites to find good prices or promotions, and that is time-consuming and frustrating to say the least.
Over time I started to get annoyed and decided to create a Python script that would search for the items/products I have listed in a Google spreadsheet across some of the major e-commerce stores in the country (South Africa).
In this post, we will learn how I created a script opens various websites (Using Selenium), searches for various items listed on a Google Spreadsheet, gets the current prices and correct item name and then uploads the data to a Google Spreadsheet, then compare the current and previous prices, if there’s a price change either send an email or slack message with item name, store and price change
The tasks involved in collecting the data are:
- Open Google Sheet using gspread, read the items
- Get all the urls for e-commerce websites
- Iterate through the urls and search for the items
- Scrape the price and update Google Sheet with price of the items
- Run a script weekly to check if there’s any price changes and then update the sheet with new price
- Notify user via email/slack with price change if there’s any.
TL;DR : See code implementation here
Web Scraping
Web scraping can be defined as: the construction of an agent to download, parse, and organize data from the web in an automated manner.
Or in other words: instead of a human end-user clicking away in their web browser and copy-pasting interesting parts into, say, a spreadsheet, web scraping offloads this task to a computer program which can execute it much faster, and more correctly, than a human can.
Web scraping is very much essential in data science field.
While many languages have libraries to help with web scraping, According to me, Python’s libraries have the most advanced tools and features.
In this post/project, I used Selenium to scrap websites such as www.makro.co.za, www.game.co.za and etc, Google sheet to store the results, travis-ci to automate it such that it runs weekly, smtp/slack for price change notification.
Why Selenium instead of Beautiful Soup
Web scraping with Python often requires no more than the use of the Beautiful Soup to reach the goal. Beautiful Soup is a very powerful library that makes web scraping by traversing the DOM (document object model) easier to implement. But it does only static scraping. Static scraping ignores JavaScript. It fetches web pages from the server without the help of a browser. You get exactly what you see in “view page source”. If the data you are looking for is available in “view page source” only, you don’t need to go any further. But if you need data that are present in components which get rendered on clicking JavaScript links, dynamic scraping comes to the rescue. The combination of Beautiful Soup and Selenium will do the job of dynamic scraping. Selenium automates web browser interaction from python. Hence the data rendered by JavaScript links can be made available by automating the button clicks with Selenium and then can be extracted by Beautiful Soup or find data by html class id.
See my previous post on how to install python-selenium or run
pip install selenium
Searching items with Selenium
Here, Selenium accesses the Firefox browser driver and without actually opening a browser window (headless argument), disabled image and flash rendering to load pages fast.
class WebDriverSetup:
def __init__(self, url, headless):
self._timeout = TIMEOUT
self._options = Options()
self._options.headless = headless
self._profile = self._disable_Images_Firefox_Profile()
self.driver = webdriver.Firefox(
firefox_profile=self._profile, options=self._options, timeout=self._timeout
)
if self._options.headless:
self.logger.info("Headless Firefox Initialized.")
try:
# Navigate to the makro URL.
self.logger.info(f"Navigating to {url}.")
self.driver.get(url)
except TimeoutException:
self.logger.exception("Timed-out while loading page.")
self.close_session()
sys.exit(1)
else:
# Obtain the source
self.html = self.driver.page_source
self.soup = BeautifulSoup(self.html, "html.parser")
self.html_source = self.soup.prettify("utf-8")
def _disable_Images_Firefox_Profile(self):
# get the Firefox profile object
firefoxProfile = webdriver.FirefoxProfile()
# Disable images
firefoxProfile.set_preference("permissions.default.image", 2)
# Disable Flash
firefoxProfile.set_preference(
"dom.ipc.plugins.enabled.libflashplayer.so", "false"
)
# Set the modified profile while creating the browser object
return firefoxProfile
First, we will use Selenium to automate the inserting of characters/product name(s) into the search bar and button click(s) required for searching useful data.
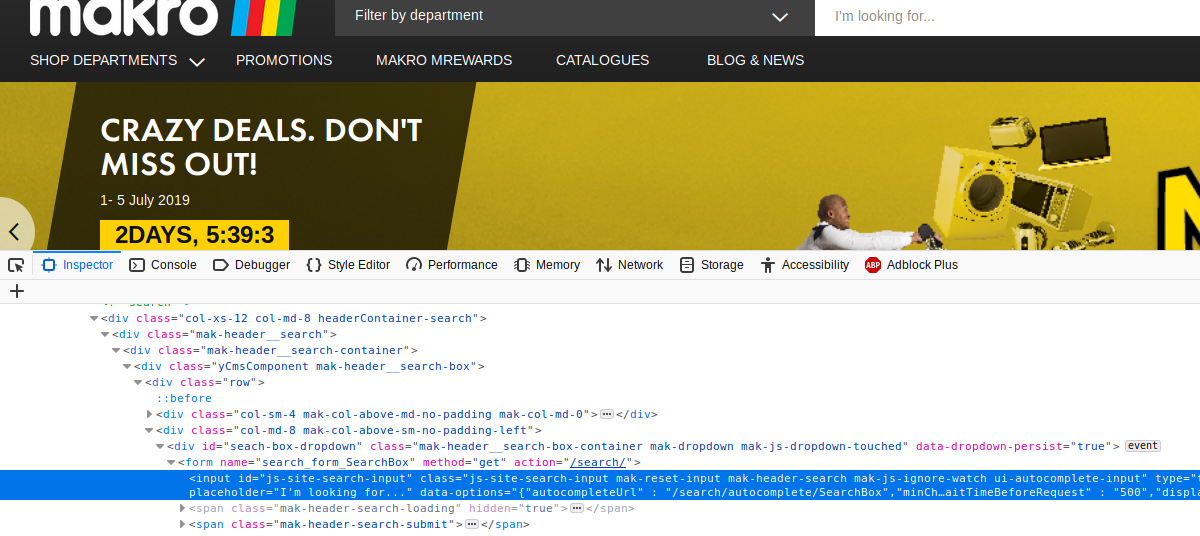
But in order to do this, we need to find the search-input-id (js-site-search-input) and use this to search for the items by sending the Return/Keyboard Enter key, this will return a new page with the searched items.
self.logger.info(
f"Searching on url: {self.url} for item #{count}: {self.item}..."
)
try:
search_input_id = self.ids[self.url.split(".")[1]]["search_input_id"]
self.logger.debug(f"inserting {self.item} on search bar")
search_input = WebDriverWait(self.driver, self._timeout).until(
EC.presence_of_element_located((By.ID, search_input_id))
)
except Exception:
self.logger.error(f"Could not insert {self.item} to the search bar.")
else:
search_input = self.driver.find_element_by_id(search_input_id)
search_input.send_keys(self.item)
self.logger.info(f"Now searching for {self.item}.")
search_input.send_keys(Keys.RETURN)
After searching for a product, we need to automate the selection by clicking on the first item on the list/grid by finding the item XPATH and automating a mouse click on the item.
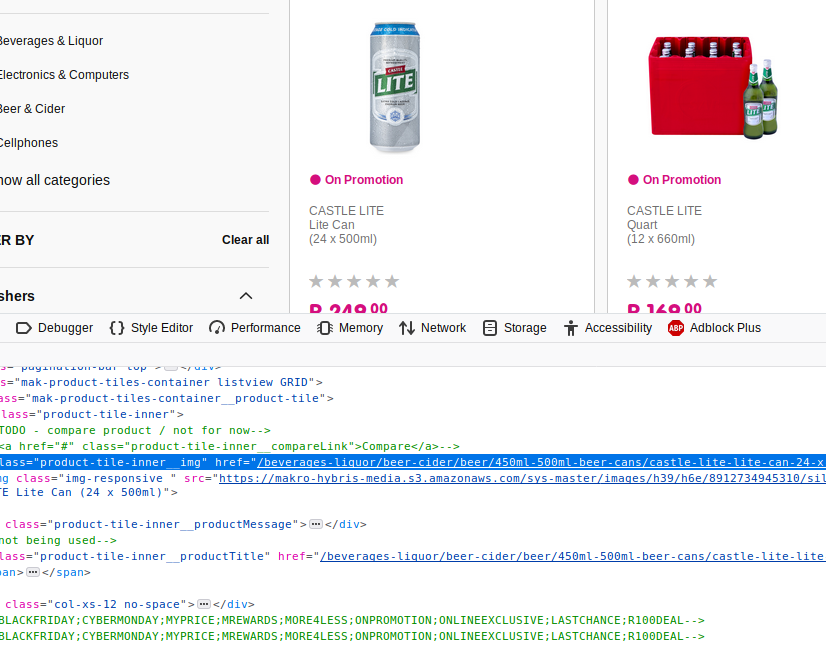
The code below, finds the element by XPath and the clicks the link which then redirects to the items page which contain product name, price and most importantly the direct url which will be useful when we update the prices.
try:
self.logger.debug("Selecting first result and open link, using xpath")
first_result_xpath = self.ids[self.url.split(".")[1]][
"first_result_xpath"
]
first_res = WebDriverWait(self.driver, self._timeout).until(
EC.presence_of_element_located((By.XPATH, first_result_xpath))
)
except Exception:
self.logger.error("No Data Available")
else:
first_res = self.driver.find_element_by_xpath(first_result_xpath)
first_res.click()
Extracting data
The page source received from Selenium now contains the product name and price, either use Beautiful Soup or locate divs / class containing the product price and name.
def get_product_price(self):
"""Gets and cleans product item price on the makro page."""
price = None
try:
price = self.driver.find_element_by_class_name(
self.ids[self.url.split(".")[1]]["price_promotion"]
).text
time.sleep(0.5)
assert isinstance(price, str) and price != ""
except Exception:
self.logger.debug(f"{self.item} is not on promotion, getting normal price.")
time.sleep(0.5)
prod_price = self.ids[self.url.split(".")[1]]["price_product"]
try:
price = WebDriverWait(self.driver, self._timeout).until(
EC.presence_of_element_located((By.CLASS_NAME, prod_price))
)
except Exception:
self.logger.error(
f"Price information for {self.item} could not be retrieved."
)
return
else:
price = self.driver.find_element_by_class_name(prod_price).text
In the next post, I will document how I managed to connect to Google sheets and push data to the sheet as well as running it as a cronjob on travis-ci.
Conclusion
Selenium with Beautiful Soup does a perfect job of web scraping. Selenium is very useful when navigating to webpages. And finally after collecting the data, you can feed the data for data science work.
The code covered in this article is available as a Github Repository.