
The Story
As a Data Engineer, one of the core responsibilities is to ensure the optimal utilization of resources and minimize costs while performing data related work such as extractions and transfers.
In this step-by-step guide, I’ll walk you through the process I followed when extracting tables from MicroSoft SQL Server, prioritizing the extraction based on data volume, concurrent connections, and more, and then efficiently storing the data on our Enterprise Data Lake running on AWS.
The How
Step 1: Analyze the Current Extraction Process
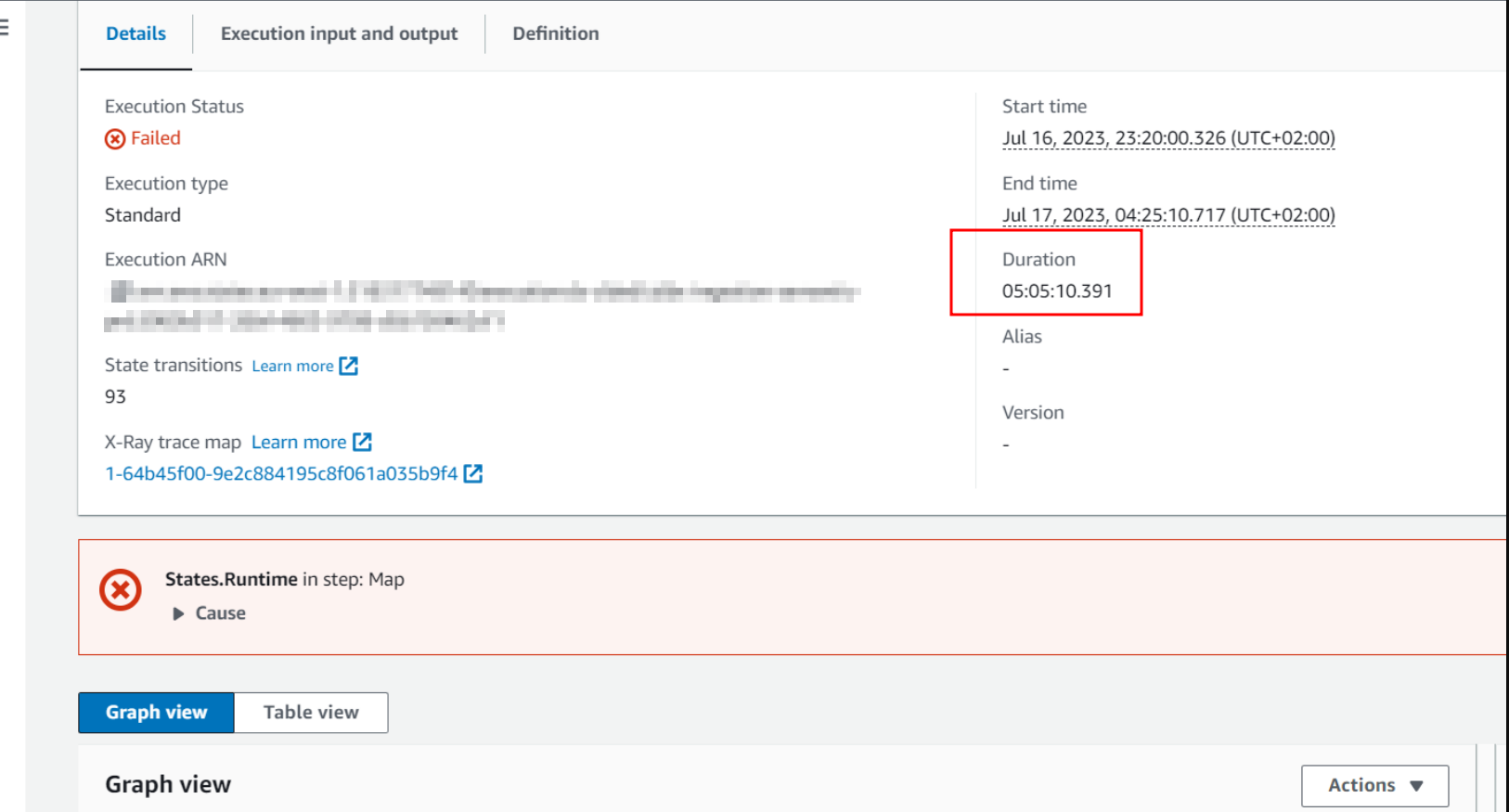
Start by reviewing the existing data extraction process to understand its limitations and bottlenecks. By Identifying bottlenecks to understand where improvements are needed and paying attention to tables with high data volume and long extraction times. The image below shows an extraction run that timed out after 5 hours due to various bottlenecks:
- Concurrent connections set to 2
- No-Parallel data transfer configurations
- Chronological table extraction instead of extracting large & small tables concurrently
- Daily Full-Extractions instead of incremental extractions (HWM)
Analyzing Resource Costs
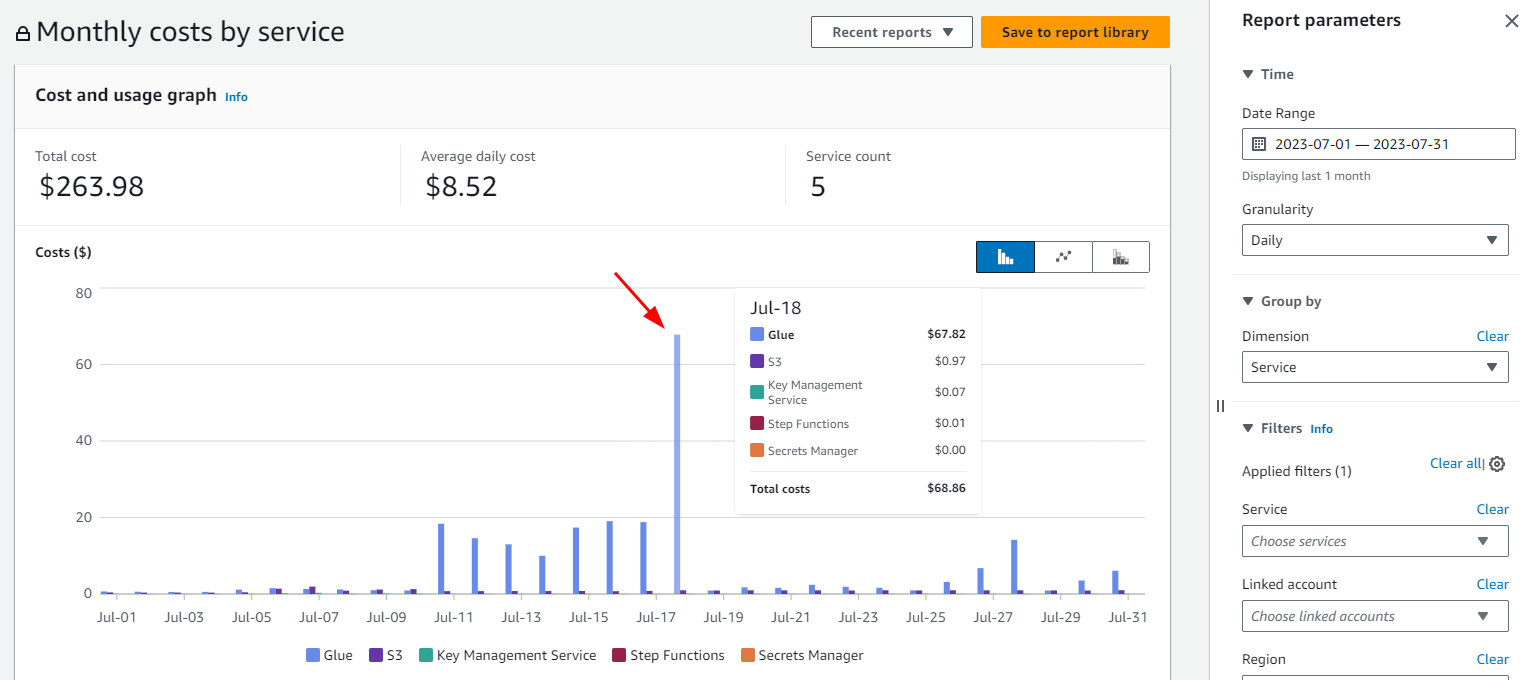
One of the core responsibilities when working with ETL jobs is to monitor and manage the cost of data operations. AWS provides a powerful tool, the AWS Cost Management and Billing Console, used to monitor resource costs effectively. This console offers insights into your team’s service usage and associated costs, empowering you to make informed decisions.
In the image below you will notice a sharp spike on the day the extraction job timed out. Imagine if I did not review the extraction job the following morning? The cost would have skyrocketed due to prolonged resource usage and inefficiencies.
Step 2: Analyze Data Volume and Frequency
The first step was to identify the tables that need to be extracted and evaluate their data volume. Prioritize the extraction of large tables with higher data volume, as these may require more time for processing and should be addressed first. The SQL script below will provide a clear overview of the table’s size and record count.
USE SEMANTIC;
SELECT
t.TABLE_CATALOG + '.' + sche.name + '.' + tbl.name AS FullTableName,
SUM(PART.rows) AS TableRecordCount,
CAST(ROUND(((au.data_pages) * 8) / 1024.00 / 1024.00, 2) AS NUMERIC(36, 2)) AS TotalSpaceGB
FROM
sys.tables AS tbl
INNER JOIN INFORMATION_SCHEMA.TABLES AS t
ON t.TABLE_NAME = tbl.name
INNER JOIN sys.partitions AS PART
ON tbl.object_id = PART.object_id
INNER JOIN sys.indexes AS IDX
ON PART.object_id = IDX.object_id
AND PART.index_id = IDX.index_id
INNER JOIN sys.schemas AS sche
ON sche.schema_id = tbl.schema_id
INNER JOIN sys.allocation_units AS au
ON PART.partition_id = au.container_id
WHERE
IDX.index_id < 2
AND patindex('%[0-9]%', tbl.name) = 0
AND patindex('%tmp%', tbl.name) = 0
AND patindex('%dev%', tbl.name) = 0
GROUP BY
t.TABLE_CATALOG + '.' + sche.[name] + '.' + tbl.[name],
CAST(ROUND(((au.data_pages) * 8) / 1024.00 / 1024.00, 2) AS NUMERIC(36, 2))
ORDER BY
CAST(ROUND(((au.data_pages) * 8) / 1024.00 / 1024.00, 2) AS NUMERIC(36, 2)) DESC;
Step 2: Consider Data Dependency
Another avenue was to check for any dependencies between tables and determine the correct order for extraction to maintain data integrity. Some tables may rely on data from others, and extracting them out of order could lead to data inconsistencies. By identifying Foreign key relations, analyzing views, stored procedures and functions.
Step 3: Evaluate Concurrent Connections
It’s essential to assess the number of concurrent connections available for extraction. Based on this evaluation, optimize the extraction process to make the most efficient use of concurrent connections.
On SQL Server
Evaluate if the server supports JDBC concurrent connections, you can check the maximum number of concurrent connections allowed by the SQL server using the query below, where 0 means there is no limit on the number of connections.
SELECT value AS MaxUserConnections
FROM sys.configurations
WHERE name = 'user connections';
You can also evaluate if the server MaxDOP (Maximum Degree of Parallelism) is configured - a setting that controls the maximum number of processors used to execute a single query in parallel. Not this may or may not directly impact JDBC concurrent extractions, as it depends on workloads and query complexities and patterns. But worth evaluating, note that by default MSSQL’s MaxDOP is set to 0 - allowing the DB engine to use all available processors. Using the SQL code below, you can confirm if it is set.
EXEC sp_configure 'max degree of parallelism';
Keep in mind that the number of concurrent connections a server can handle depends on various factors, including hardware resources, memory, CPU, and the workload on the server. It’s essential to monitor the server’s performance, and potential query blocking after MaxDOP changes and adjust the maximum connections accordingly to avoid resource contention and performance issues.
On AWS Glue
Current JDBC concurrent connections were initially set to 10 (for testing purposes),
resulting in the image shown below. An analysis of the table extraction and duration is detailed in How to Visualize EDL2.0’s Step Functions Data
Step 4: Utilize AWS Glue for Parallel Processing
Leverage the power of AWS Glue’s Extract, Transform, Load (ETL) capabilities to parallelize reads and significantly speed up the extraction process. By using multiple AWS Glue worker nodes, you can achieve efficient parallel processing for faster data extraction.
Some of the ways you can utilize Glue for parallel processing includes:
- Use a good partitioning strategy: Partitioning the data by a high cadinality columns such as
dateor abigintcan help to improve the performance of queries that need to be run on the data - Define Parallelism: In your Glue job settings, set the number of workers (parallelism) that AWS Glue should use for processing. This can be adjusted based on the available resources and the complexity of the extraction.
- Using a better worker node: In your Glue job settings, set the
WorkerTypefromG.1Xto a bigger instance
Step 5: Implement Data Security Measures
Identify tables that contain sensitive or regulated data and implement appropriate security measures to protect this information during the extraction and migration process.
Step 6: Plan for Data Growth
Anticipate future data growth over the next 1-5 years to accommodate scalability needs. Prioritize the extraction of tables that have significant growth potential, ensuring your data lake can handle future expansions.
Results After Optimizations
In a significant stride toward improving data extraction efficiency, I successfully transformed a time-consuming 5-hour MSSQL table extraction process of over half a Billion records (60GB) into a streamlined 44-minute operation costing an average $12.51. This achievement was realized through careful analysis, strategic configuration changes, and the integration of advanced technologies.
The initial challenge was a linear extraction approach, where tables were fetched chronologically and in alphabetical order. To address this bottleneck, I thoroughly reviewed best practices and documentation. After comprehensive testing, we initiated an optimization effort that aimed to redefine our data extraction process.
One key change involved reordering the extraction sequence. By simultaneously extracting 3x small and 2x large tables, we harnessed parallel processing to significantly reduce extraction times. This strategic arrangement allowed us to maximize our system’s resources, efficiently fetching data from multiple tables concurrently.
Another enhancement leveraged Spark JDBC parallel reads. Through careful configuration of Spark parameters such as partitioning and fetch size, we increased data retrieval speed. These adjustments were guided by thorough scrutiny of documentation and rigorous testing to ensure alignment with our specific requirements.
The final improvement entailed scaling up our AWS Glue workforce. By increasing the NumberOfWorkers to 5 and using the WorkerType G.2X, we enhanced processing power and computational efficiency. This change had a profound impact on the extraction process, enabling each worker to compute input data partitions more efficiently.
In conclusion, my journey from a time-consuming 5-hour extraction to a swift 44-minute achievement underscores the potential of data engineering innovation. By careful planning, informed configuration changes, and harnessing modern technologies, we not only achieved optimal extraction times but also elevated the overall efficiency and performance of our data ecosystem.