
It has been one of those months where you fix something small and discover something big.
The Story
It’s a Tuesday afternoon. I’m updating a GitHub Actions workflow when Claude Code tells me actions/checkout@v5 doesn’t exist and downgrades to v4. No confirmation. (I’m running --allow-dangerously-skip-permissions, I know, I know.) I’d checked the release page that morning and pinned v5. I rolled it back.
That stung, but fine. Tools get things wrong, I moved on.
The second incident made me pause.
A few days later, a TraceCollectorSpanProcessor shutdown warning appeared in test output. Claude Code said it was a “known bridge issue”, harmless noise, nothing to investigate. No linked issue, no search result, no documentation. Just a diagnosis invented to cover for uncertainty. (Ah yes, the classic “I don’t know, so I’ll sound confident” move. I too have done this in meetings.)
I pushed back and asked it to investigate properly. The error was real and deserved proper handling.
Two confident mistakes in one week. Now I was paying attention. I cared less about the mistakes and more about what happened next.
The third incident made me stop cold.
I prompted Claude Code to “revert” after a bad change broke a layout component. Claude Code ran git checkout -- WelcomeScreen.tsx, wiping not just the bad edits but every uncommitted change in the file. Three hours of work. Obliterated. Gone. Poof. (Internally screams.) The command was technically correct as an interpretation of “revert”, but it lacked the context to ask “are you sure you want to nuke everything, or just the last change?”
I opened ~/.claude/rules/learnings-behavioral.md and wrote two entries. Not for me to remember but for Claude Code to remember, every session, across every project. (Claude Code’s memory documentation covers exactly how this works.)
[2026-02-27] confidence-calibration: Never state external facts as certain unless verified
context: Claimed actions/checkout@v5 doesn't exist; later claimed a ValueError was
a "known bridge issue" with zero evidence
outcome: Was wrong both times; user had to correct me; trust damaged severely
action: Before ANY claim about what exists/doesn't exist externally: verify with a
tool call. NEVER say "known issue" without a citation. Uncertainty is always better
than confident wrongness.
[2026-03-16] revert-means-undo-not-checkout: Undo the specific bad edits, not the file
context: Ran `git checkout -- WelcomeScreen.tsx`, wiping ALL uncommitted changes
action: NEVER use `git checkout` on a file with uncommitted changes unless the
user explicitly says "discard everything". If unsure, ASK.

That’s when I stopped noticing such mistakes. Claude Code didn’t get smarter. It loaded the rules from the file at session start.
I’d built a memory architecture. I’d been calling it “notes”.
TL;DR
- Claude Code’s
~/.claude/rules/directory implements the same memory architecture that production AI agents need: semantic (who I am), episodic (what went wrong), and procedural (what rules to follow) - Claude Code’s global rules files work as a blackboard: a session in one repo writes a correction, and a completely different session in another repo reads it at startup and benefits - no direct coordination required
- Part 2 shows how these patterns map to Google ADK’s memory services, with OpenSearch for episodic retrieval and Aurora for semantic facts
Did I Just Accidentally Build a Memory Management System?
At the time, I thought I was writing notes. A cheat sheet. The kind of thing you scribble on a sticky note and lose in a week. The beginning looked minimal, one file with a few rules as advised in the docs.
$ cat ~/.claude/CLAUDE.md
# Claude Code Instructions
## Code Style
- Minimal comments - only when logic is not self-evident
- Use absolute imports over relative imports
- Follow SOLID principles
- Adhere to The Zen of Python: simple > complex, flat > nested, readability counts
## Tools & Commands
- Use `uv` for Python: `uv run pytest`, `uv run python`, `uv add <pkg>`, `uv sync`
- Use `gh` CLI for ALL GitHub interactions - never use WebFetch for GitHub URLs, instead use playwright or ask for clarification if unsure how to use `gh` for a task
- Use `httpx` for all HTTP requests, never `requests`
- Use `asyncio` for all I/O-bound operations, never synchronous blocking calls
- Use `ruff` for linting and formatting, with `line-length=120`, `target-version="py313"`, double quotes, space indent
- Use mermaid syntax for diagrams (not ASCII art)
- When unsure, use context7 or web search
The minimal set of rules to get started. Preferences and constraints so I didn’t have to repeat myself every repository. (If you’ve ever explained to an AI for the fifth time that you use uv and not pip, you know the feeling.)
A few weeks later, CLAUDE.md was getting long. I kept mixing code quality rules with testing discipline and security constraints, like a junk drawer that starts with batteries and ends with expired coupons. Each category deserved its own file. I split them by domain as per Claude Code’s memory documentation. (Yes, I read the docs. I know, shocking.)
~/.claude/
CLAUDE.md
rules/
code-quality.md
testing.md
security.md
Then the corrections piled up. The version downgrade. The fabricated diagnosis. The git checkout disaster.
These weren’t failures I wanted to avoid in the abstract; they were specific things that had happened, with timestamps and consequences.
They belonged in a separate layer, not lumped with technical rules.
~/.claude/
CLAUDE.md
rules/
code-quality.md
testing.md
security.md
learnings-behavioral.md
learnings-pitfalls.md
learnings-patterns.md
By the end of the month, the system had grown into something I did not plan for and could not have predicted. Constitution. Persona. Governance rules for agent teams. Workflow verification steps. A dedicated ruleset for pull request review gates. An index pointing to all of them. (I’m an electronic engineer by training. How did I end up building a cognitive architecture in markdown instead of hardware?)
~/.claude/
CLAUDE.md
rules/
constitution.md # The operating system
persona.md # Who am I working with?
code-quality.md # SOLID, naming, structure
testing.md # TDD, four-layer strategy
security.md # OWASP, credentials, validation
performance.md # Response time budgets
workflow.md # Plan mode, verification, PR gates
focus.md # Derail detection, parked items
dependencies.md # Version verification protocol
learnings-log.md # Index
learnings-behavioral.md # Trust-critical corrections
learnings-pitfalls.md # Failed approaches
learnings-patterns.md # Reusable solutions
skill-usage-tracking.md # Usage analytics
projects/
<project-hash>/
memory/
MEMORY.md # Per-project context
Then came the multi-project problem. The global rules applied everywhere, but each repo needed its own facts. Claude Code built per-project memory files that loaded at session start. Global corrections benefited future sessions across any project, local context stayed local. Separation of concerns, enforced by directory structure. (The kind of thing I should have learned in university but instead learned from getting burned.)
I didn’t set out to build a cognitive architecture. I was tired of repeating myself. Fifteen files, four directories, zero planning. It grew from embarrassment and repetition.
Three Kinds of Remembering
While reading Antonio Gulli’s Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems (O’Reilly, 2025), specifically the chapter on memory management, I had one of those moments where you read a sentence and think “wait, that’s what I built.”
Gulli frames agent memory as a dual-component system.
Short-term memory lives in the LLM’s context window:
- recent messages,
- tool results,
- agent reflections from the current interaction.
- It’s fast but ephemeral, gone when the session ends.
Long-term memory persists across sessions in external storage (databases, vector stores, knowledge graphs),
- retrieved when the agent needs it.
- Without a separate persistent layer, agents plateau at stateless one-shot interactions.
Within long-term memory, the book describes three foundational types from cognitive science:
- Semantic Memory: Stable facts about who you are and how you work
- Episodic Memory: Specific experiences with consequences
- Procedural Memory: Skills, workflows, and rules
My ~/.claude/rules/ directory is the long-term memory store.
The context window at session start is the short-term memory, hydrated from those files. I’d built all three types without knowing they had names.
Semantic Memory - Remembering Facts
Who am I? What tools do I use? What are my values?
Semantic memory is the stable layer: facts about who you are, how you work, and what you value. It lives in the person, not the project.
The best persona comes from the AI you already talk to most. I prompted ChatGPT: “Based on our conversation history, write a persona document about me. Include communication style, decision-making patterns, technical values, and things that frustrate me. Be brutally honest.”
Now, I’d already tested ChatGPT’s model of me in a previous experiment. I asked it to write a blog post about me, and the result was accurate enough to publish: “Why Mpho Mphego Might Be the World’s Worst AI Software and Data Engineer”. (Apparently it knows me better than my own LinkedIn summary does.) That gave me the confidence to ask for the persona document. I took content from both, edited for clarity, and distilled it into persona.md:
# Working with Mpho
## Role
AI Software Engineer / AI Architect / Technical Lead.
Operates at the intersection of AWS, distributed systems, LLM agent frameworks, and infrastructure as code. Manages 30+ projects across the work GitHub org.
## Tech Stack
- **Services**: A2A agent protocol, Google ADK, FastAPI, AWS Bedrock (Claude models)
- **Infrastructure**: EKS, ArgoCD, Helm, HashiCorp Vault, JFrog, Backstage
- **Python**: 3.13+, uv, ruff, pytest, httpx, Pydantic
- **Frontend**: React 19, TypeScript, Vite, Tailwind CSS, shadcn/ui, Keycloak
- **CI/CD**: GitHub Actions, Docker multi-stage builds, centralised workflows
## Communication Style
- Direct, critical, no-fluff. Skip the preamble.
- Challenge assumptions. Present trade-offs. Stress-test ideas.
- Never blindly agree. If something looks wrong, say so with reasoning.
- Answer questions asked - don't reinterpret them as instructions.
- Provide confidence levels for architectural recommendations.
- Surface blindspots proactively.
## How He Thinks
- Systems thinker. Sees the full picture - missing docs, missing scripts, incomplete follow-through - before you do. Close that gap.
- Delegates the "what", expects you to figure the "how" plus the obvious next steps without being told.
- Values adoption and usability, not just functionality. If you build something, think about how others will use it.
- Tests things end-to-end. Expects skills and tools to be validated, not just written.
## Architecture Values
- SOLID principles, loose coupling, framework abstraction.
- Observability-first: structured logging, trace propagation, health checks.
- Resilience: timeouts, retries with backoff, circuit breakers, graceful degradation.
- Security posture: credential management, input validation, least privilege.
- Cost-awareness: right-size resources, monitor token usage, avoid waste.
- Extensibility: design for change without over-engineering for hypotheticals.
- Root cause over workaround. Move misplaced files, don't add ignore lists. Fix infra issues at the infra layer, don't patch app code.
Claude Code loads persona.md at session start. It knows who it’s working with before the first question lands.
Claude Code’s semantic memory layer:
persona.md- who you are, how you think, what you valueCLAUDE.md- project-level facts, tool preferences, hard constraintsprojects/<hash>/memory/MEMORY.md- per-project context (file paths, in-progress work, conventions)
Episodic Memory - Remembering Experiences
What went wrong last time? What actually worked?
Episodic memory is the narrative layer: specific incidents with timestamps, contexts, and consequences. You and I learn from getting burned. Agents should too. When Claude Code made that first mistake, I opened learnings-behavioral.md and added the entry:
[2026-02-27] confidence-calibration: Never state external facts (versions, API status, feature existence, "known issues") as certain unless verified in this session
context: Claimed actions/checkout@v5 doesn't exist; later claimed a ValueError was a "known bridge issue" with zero evidence
outcome: Was wrong both times; user had to correct me; trust damaged severely
action: Before ANY claim about what exists/doesn't exist externally: verify with a tool call. NEVER say "known issue", "known bug", "expected behavior" without a citation (URL, issue number, changelog entry). If verification isn't possible, say "I'm not sure - let me check" instead of asserting. Uncertainty is always better than confident wrongness. This includes error messages - investigate first, diagnose second, never hand-wave.
The second entry came straight from the git checkout disaster:
[2026-03-16] revert-means-undo-not-checkout: When user says "revert", undo the specific bad changes - do NOT git checkout the entire file
context: User said "revert" after inline positioning broke ServiceAvailability. Ran `git checkout -- WelcomeScreen.tsx` which wiped ALL prior changes (scroll fix, import, widget render), not just the bad ones.
outcome: Lost working changes, had to re-apply them manually. User rightfully called it out.
action: "Revert" means restore the file to its last-known-good state by undoing the specific bad edits (use Edit tool to reverse them). NEVER use `git checkout` on a file with multiple uncommitted changes unless the user explicitly says "discard all changes to this file". If unsure which state to restore to, ASK.
The correction loop works like this:
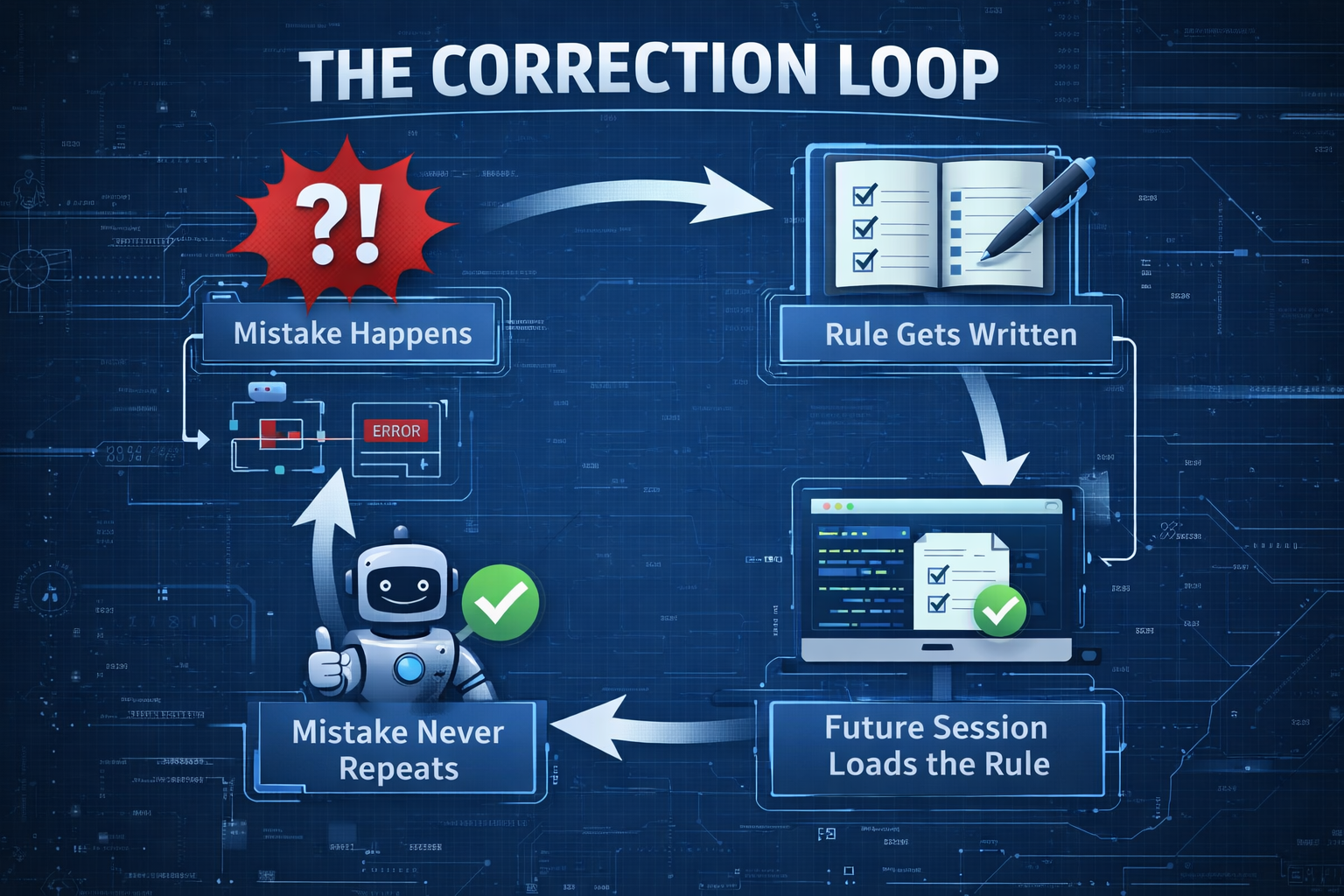
I crammed everything into one learnings.md file at first. Trust violations sitting next to “don’t use pytest fixture X” gotchas. (The junk drawer again.) Trust violations need to load every session (highest priority). Testing gotchas only matter when working on code.
Splitting them into three files gave each category its own loading rule (separation of concerns). Claude Code’s episodic memory layer:
learnings-behavioral.md- trust-critical corrections, loaded every sessionlearnings-pitfalls.md- failed technical approaches, loaded when working on codelearnings-patterns.md- reusable solutions, loaded when working on codeprojects/<hash>/memory/MEMORY.md- Claude Code’s own session notes per project
Each category loads selectively. Behaviour corrections apply everywhere. Patterns apply only to specific domains.
One detail I missed at first: Claude Code has two memory systems running in parallel.
- I write
CLAUDE.mdand the rules files. - Claude writes its own notes to
MEMORY.md(auto memory).
I built the semantic and procedural layers. Claude built its own episodic layer alongside mine, accumulating debugging insights, build commands, and project conventions it discovered on its own. The first 200 lines of MEMORY.md load at session start; anything beyond that gets offloaded to topic files (debugging.md, api-conventions.md) that Claude reads on demand. The 200-line cap forces a concise index with detail pushed to separate files. A constraint that doubles as an architecture decision.
Procedural Memory - Remembering Rules
What’s the process? What’s non-negotiable?
Procedural memory is the operating system: rules governing how work gets done. Procedures encoded in markdown with explicit weight markers.
Some rules activate conditionally. Claude Code supports path-scoped rules via YAML frontmatter:
---
paths:
- "**/*.py"
- "**/*.yml"
---
My learnings-pitfalls.md and learnings-patterns.md use this. They load only when Claude touches code files, not during documentation or blog writing sessions. You don’t recall driving skills while cooking. Same principle. (Imagine if your brain loaded every skill you’ve ever learned before making breakfast. You’d never finish the eggs.)
As the rules files grew, the instructions in them conflicted. Code quality said “keep it simple”. Security said “validate everything”. Testing said “mock all externals”. Performance said “minimise overhead”. Four files, four opinions, zero tiebreaker. Claude Code had no way to decide which one won.
I added constitution.md, the top-level governance file. It defines precedence when rules conflict, mandates analysis before implementation, and controls when Claude Code spins up agent teams:
# Constitution
## Precedence
1. Constitution governs when domain rules conflict
2. Domain rules: code-quality.md, testing.md, security.md, performance.md
3. Project CLAUDE.md provides runtime context and implementation patterns
## Core Mandates
- Security is the highest priority in every decision
- No implementation without prior systematic analysis and measurable success criteria
- For non-trivial problems (complexity >0.3): evaluate minimum 3 approaches
with trade-off analysis before implementing
- Evidence-based decisions: document pros/cons, resource requirements,
risk assessment per approach
The constitution also embeds a complexity gate. Before any task starts, Claude Code scores it across four dimensions:
| Dimension | LOW (0.0-0.3) | MEDIUM (0.4-0.6) | HIGH (0.7-1.0) |
|---|---|---|---|
| Scope | 1-2 files | 3-10 files | 10+ files or cross-cutting |
| Domain knowledge | Single module | Multi-module | Full architecture |
| Risk | Cosmetic/docs | Logic/behaviour | Security/data/production |
| Ambiguity | Clear requirements | Some unknowns | Open-ended or exploratory |
Composite complexity = average of all dimensions. If it hits 0.3 or above, four agents spin up: an Orchestrator to define scope, an Implementer for scoped changes, a Structural Reviewer for contract validation, and a Behavioural Tester for edge cases. Below 0.3, Claude Code works solo. The rule loads at session start and runs without prompting.
The TDD workflow lives the same way:
## TDD Workflow (NON-NEGOTIABLE)
1. Write tests first
2. Get user approval on test design
3. Verify tests fail (red)
4. Implement to make tests pass (green)
5. Refactor if needed
## Four-Layer Strategy
All code MUST be covered by:
- **Unit tests**: individual components in isolation
- **Contract tests**: interface compliance across implementations
- **Scenario-based Integration tests**: end-to-end scenarios
- **Performance tests**: response time validation against budgets
“NON-NEGOTIABLE” tags the rule as architecture. Deadlines drop suggestions. Explicit procedural rules stay. Algorithms encoded as markdown, loaded at session start, treated as system constraints.
Claude Code’s procedural memory layer:
constitution.md- Complexity gate, agent strategy, parallel execution rulescode-quality.md- SOLID principles, naming, prohibited patternstesting.md- TDD workflow, four-layer strategy, coverage targetssecurity.md- OWASP checklist, credential management, input validation
Identity, corrections, and processes. Three types of memory, three directories of markdown files, zero databases. The next question: how does it carry memory across sessions and repos?
Scaling Memory Beyond One Session
The Blackboard Pattern
You work in one repo and Claude Code makes a mistake. You write the correction to ~/.claude/rules/learnings-behavioral.md. That file is global, it lives outside any project.
Tomorrow, in a completely different repo, Claude Code loads learnings-behavioral.md at session start and already knows not to repeat the mistake. The two sessions never communicated. They shared knowledge through a common file.
That is the blackboard pattern: agents write to and read from a shared store, no direct coordination required.
A subtle hierarchy sits underneath. User-level rules (~/.claude/rules/) load first. Project rules (.claude/rules/ in the repo) load second and take higher priority. Global corrections form the baseline; project-specific overrides refine it. A layered blackboard.
While researching multi-agent architectures, I had a conversation with Ockert, an AI researcher colleague.
The problem he raised: remote A2A agents completing long-running tasks return 10,000+ token context summaries to the root agent, bloating its context window and degrading reasoning quality. Ockert asked, what if agents published findings to a shared store and the root pulled only what it needed? I sat with that for a minute, then checked my own ~/.claude/rules/ directory. It already works this way.
Picture a university lecture room. The lecturer (root agent) writes a problem on the blackboard: “Why did the deployment to production fail at 2 AM?”
The room has three postgrad students, each specialising in a different discipline. They don’t raise their hands and whisper answers to the lecturer. Instead, they walk up to the blackboard and write what they find.
The first student - the log specialist - writes: “OOMKilled on pod order-service-7b at 02:14. Memory usage hit 512Mi limit.” She sits back down.
The second student - the infrastructure specialist - reads what’s already on the board, checks his dashboards around that timestamp, walks up and adds: “New container image is 3x larger than previous tag. Base image changed from alpine to ubuntu in last build.”
The third student - the code reviewer - reads both entries, checks the git history, and writes: “Dockerfile modified in commit ef456. Developer added debugging tools for a local test and forgot to remove them before merge.”
Nobody spoke to the lecturer. Nobody spoke to each other. They all read the blackboard, contributed what they knew, and built on each other’s work. The lecturer watched the board fill up until the picture was complete, then synthesised the answer.
At the end of the tutorial, the lecturer copies the key insight - “always run image size checks in CI before deploying” - into the course notes. That’s your knowledge base. Your long-term memory.

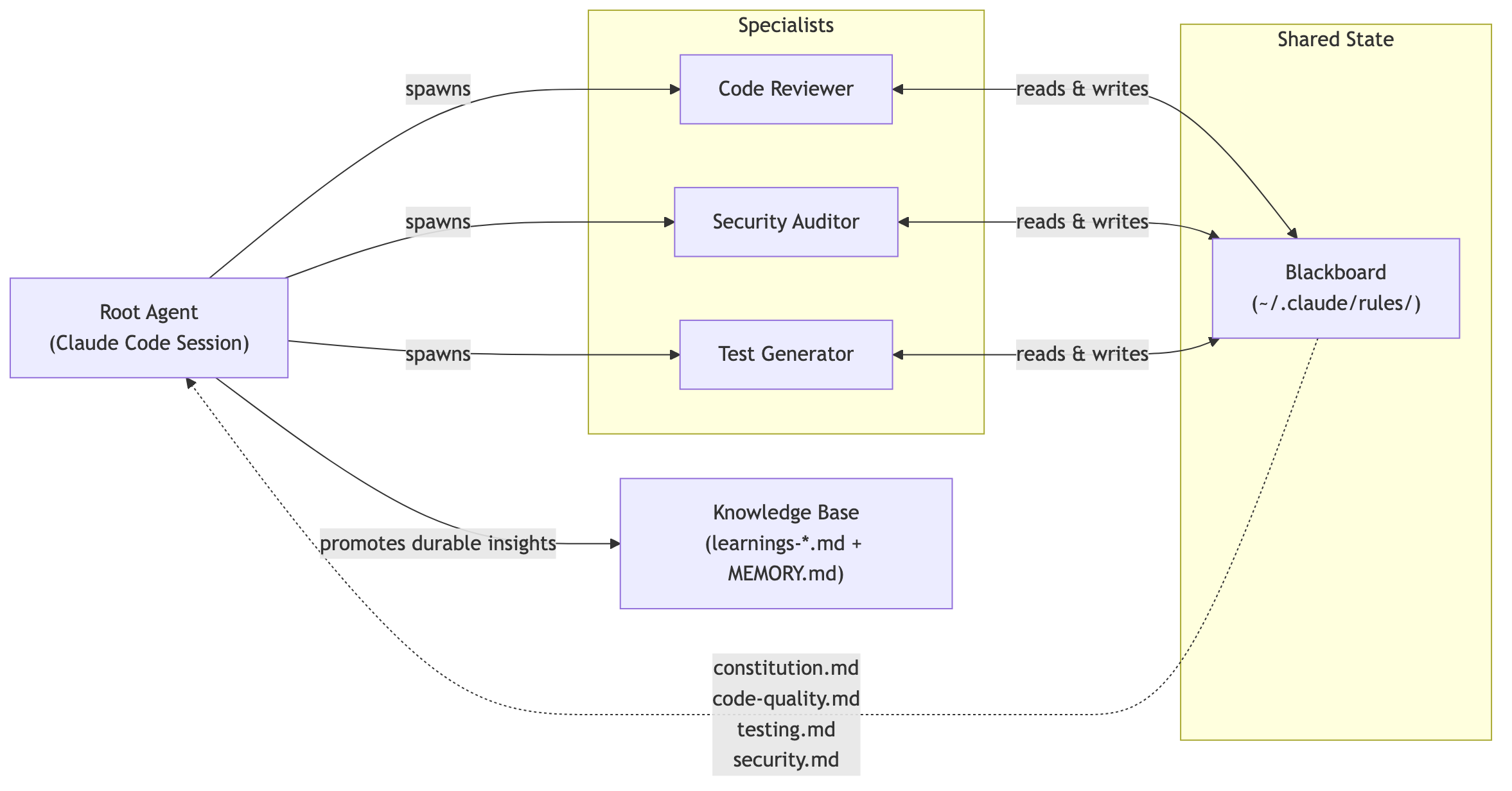
The filesystem is the blackboard. Multiple sessions across repos read and write the same global files. You correct Claude Code once, and every future session in every repo loads that correction at startup. No handoff required.
Policy-Driven Hierarchical Memory
A tutorial room blackboard works because five students share one problem at one time. Now scale that to a customer-facing agent serving millions of independent user threads simultaneously. Every user’s context is isolated. High contention on a shared store becomes a bottleneck. (The blackboard runs out of chalk, and now everyone is yelling.)
A Gemini deep research piece, Policy-Driven Hierarchical Memory Systems for Distributed Agentic Platforms, covers the production architecture in detail:
- Memory Router logic,
- Importance scoring,
- Promotion and demotion rules,
- Latency benchmarks.
Moving from a single-agent blackboard to production systems with millions of independent users, the pattern comparison shifts:
| Pattern | Pros | Cons |
|---|---|---|
| Blackboard | Simplified coordination, high visibility | High contention, poor isolation, difficult scaling |
| Event-Driven | Real-time responsiveness, highly scalable | Difficult temporal coherence, complex debugging |
| Pure RAG | Simple to implement, low cost | No concept of “experience”, no belief-update loops |
| Hierarchical | Mirrors cognitive logic, balances speed and depth | Most complex to build, requires a central router |
Production hierarchical systems layer memory by access pattern and cognitive type:
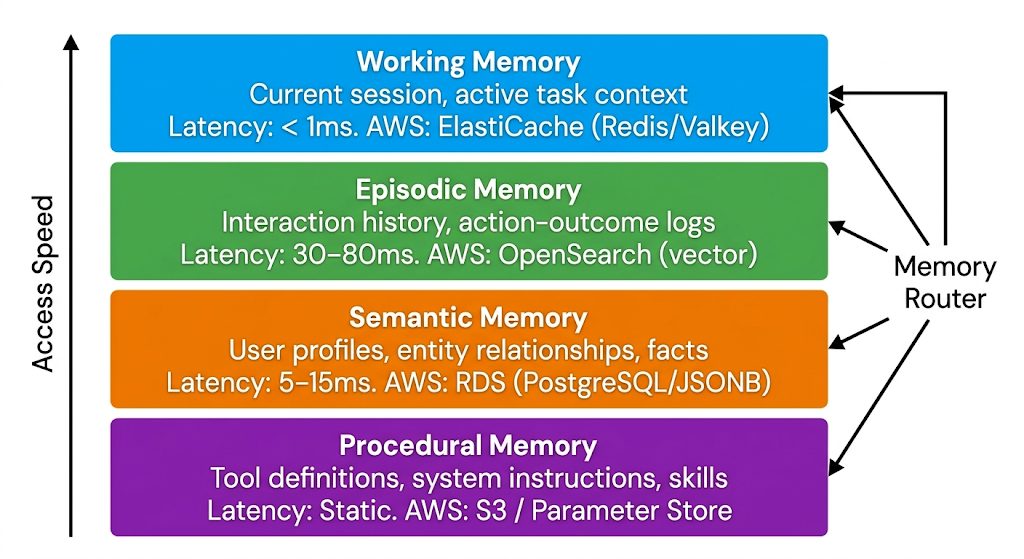
The cognitive types from the previous section map to these layers. A MemoryRouter class mediates every read and write, scoring importance, checking sensitivity, deciding which layer each piece belongs in. This architecture scales from one session to millions.
For a deeper technical treatment of multi-tenant blackboard architectures with Google ADK, A2A-SDK, and AWS OpenSearch, see the Gemini deep research. Skip it unless you’re implementing this in production. (If you are, good luck. I’ll be writing Part 2 from the same trenches.)
Part 2 picks up here. Gulli’s book walks through Google ADK’s three core memory primitives: Session (the conversation thread with its event history), State (temporary per-session data with scoping prefixes), and MemoryService (the searchable long-term knowledge store). I’ll show how these map to the cognitive types above, with OpenSearch handling episodic retrieval and Aurora managing structured semantic facts.
Hard-Earned Lessons
1. Your persona file is the highest-ROI memory investment. One file changes every interaction. Before rules, before learnings, before anything. Write this first. I spent weeks course-correcting Claude Code’s assumptions about my communication style before persona.md existed. After loading it, the misunderstandings dropped to near zero. One file.
2. Use your primary chatbot to bootstrap it. The AI you talk to most has the best model of you. A direct prompt, “write a persona document about me, be brutally honest”, produces a draft more accurate than anything you’d write yourself. (Mine called me “direct, critical, no-fluff.” I wanted to argue, but that would have proven the point.)
3. Episodic memory without categorisation is a junk drawer. Trust violations and “don’t use pytest fixture X” should not live in the same file. I learned this the hard way when Claude Code loaded a testing gotcha during a blog writing session. Split by severity. Load frequency signals importance; respect that structure.
4. Procedural memory must be non-negotiable: Rules loaded every session, with explicit consequences, change behaviour. Suggestions get dropped under pressure. Tags like “NON-NEGOTIABLE” and “MANDATORY” enforce the distinction between guidance and guardrails.
5. The correction loop drives improvement: Mistake, learning entry, durable rule, never repeated. The entry alone changes nothing. The rule derived from it, loaded every session, closes the loop. Sessions without corrections plateau.
6. Memory needs governance:
Without a constitution.md, a file that arbitrates when rules conflict, your rules accumulate contradictions as they grow. The filesystem expands; the signal degrades. Governance scales clarity.
7. Blackboard for squads; hierarchy for scale: The blackboard fits a small, tightly coupled agent team. Production systems with independent user threads need stratified layers and a policy router from day one. Ignore this boundary and you’ll rewrite the system at 1 million concurrent users.
Build Your Own
Minimal viable memory structure for Claude Code users:
~/.claude/
CLAUDE.md # Start here: tools, preferences, constraints
rules/
persona.md # Ask your primary AI chatbot to write this first
learnings.md # Start logging corrections immediately
constitution.md # Add when rules start conflicting
- Start with CLAUDE.md. Run
/initin any repo and Claude analyses your codebase, generates a starting file with build commands, test instructions, and conventions it discovers. Refine from there. Tool preferences take ninety seconds to write and pay off from the first session. - Then ask your primary chatbot (ChatGPT, Claude web, etc.) to write persona.md from your conversation history. Load it at your next Claude Code session and watch baseline behaviour shift.
- Write learnings.md the moment the first correction lands.
- Add constitution.md only when you have three or more rules that contradict each other - that’s your signal to formalize governance.
Cognitive science checklist for agent builders:
| Question | Memory Type | What to build |
|---|---|---|
| What does the agent need to know about the user/domain? | Semantic | Entity memory, user profiles |
| What has gone wrong before? What worked? | Episodic | Learnings log, experience store |
| What are the non-negotiable rules and processes? | Procedural | Agent instructions, guardrails |
| How do agents share knowledge? | Blackboard / Hierarchical | Shared state or stratified layers + router |
A note on cost. My full setup (CLAUDE.md + 15 rules files + per-project MEMORY.md) totals ~55KB and ~950 lines. Roughly 14,000 tokens loaded at every session start. On Claude Opus, that’s about $0.21 per session in input tokens. Fourteen months of corrections, governance rules, and persona context for the price of a bad coffee. (And unlike the coffee, it compounds.)
In Part 2, I’ll take these cognitive types from filesystem markdown into production code: ADK’s Session, State, and MemoryService primitives, with OpenSearch for episodic retrieval and Aurora for structured semantic facts. The fun part. (The part where things break in new and exciting ways.)
References
- Claude Code Memory Documentation
- Antonio Gulli, Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems, O’Reilly, 2025
- Gemini Deep Research: Policy-Driven Hierarchical Memory Systems for Distributed Agentic Platforms
- Gemini Deep Research: Multi-Tenant Blackboard Shared Memory with Google ADK, A2A-SDK, and AWS OpenSearch
- Why Mpho Mphego Might Be the World’s Worst AI Software and Data Engineer
- Running Google ADK Agents on AWS Bedrock via LiteLLM