Disclaimer: AI-assisted post. Structure and phrasing are Claude’s. The decisions, war stories, and 2am tequila are mine.
It was a Saturday afternoon, after driving to & from Langebaan for my daughter’s sports match (#PresentDads), everyone was on devices and the access to the living room TV and bedroom TV was gone - so I did what I do best, pulled my laptop out and deployed Maestro v2.0.0.27 to dev. I had pointed it at a backlog of issues with failing tests, and walked away to grab a beer. When I came back, both agents were running. Logs were streaming. The dashboard showed work in progress.

This is the good part, I thought.
I came back five minutes later and found this:
NAME READY STATUS RESTARTS AGE
maestro-6d8f9b7c4-kqvxp 0/1 CrashLoopBackOff 3 8m
(I should have taken a tequila shot before grabbing the beer.)
kubectl describe pod maestro-6d8f9b7c4-kqvxp told me what I needed to know:
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Sat, 19 Apr 2026 14:32:11 +0200
Finished: Sat, 19 Apr 2026 14:37:44 +0200
I had given the service 512Mi of memory. Two Claude CLI subprocesses, each injecting a 60k-token prompt payload per invocation, disagreed with that number in the most direct way possible. Exit code 137. No graceful shutdown. No warning. Just: OOMKilled.
The pod was not crashing because the code was broken. It was crashing because I had not thought hard enough about what I was actually running at scale.
This is that story. But to understand why a Saturday afternoon pod crash is a feature of the design rather than a bug in the planning, I need to start a few weeks earlier, on day two of my leave of absence.
My laptop was open. My notes app had three new pages. My spouse was giving me the look, radiating judgment from across the room.
(None of this would exist without taking actual time off. Vacation gave me the mental space to stop reacting and start designing.)
I had been reading Birgitta Böckeler’s harness engineering article and had already bookmarked OpenAI’s Symphony project on GitHub, mentally rewriting it in Python before I had even finished the README.
I had been obsessing over harness engineering for months. I’ve had Claude Code running in our workflows (reviewing code, drafting issues, suggesting refactors) but it always felt reactive for the past 5-7 months. I was prompt-engineering my way through problems that deserved structural solutions. The model was smart enough. The scaffolding around it was not.
When I found Symphony, OpenAI’s Elixir-based agent orchestrator that polls Linear for work, spins up isolated workspaces, and dispatches Codex agents until the issue is resolved, something clicked.
This was the structural pattern I had been missing. A harness, not a wrapper. And if the harness is well-designed, the agent gets better automatically every time the model does.
Two weeks later, I had Maestro (Python version). A few days after deploying it properly, I learned about memory limits and EBS volume semantics the hard way.
(It is 2am as I write this blog post. Tequila on the table. Rain outside. Sleep, I’ve decided, is for the weak.)
TL;DR
- Write GitHub issues describing what you want, not how to build it. Come back to find PRs. Your attention is no longer the bottleneck.
- Harness engineering treats agents as control systems: feedforward guides prevent failures, feedback sensors catch them post-generation
- OpenAI’s Symphony (Elixir) was the architectural inspiration; Maestro v2 is a Python rewrite pointed at GitHub Issues instead of Linear
- The harness is thin (roughly 300 lines of orchestration); the intelligence lives in a Jinja2
WORKFLOW.mdthat renders per-issue instructions - Capable of running 10 concurrent Claude CLI subprocesses will OOMkill a 512Mi pod faster than you think; 2Gi is the floor for anything real
- On EBS ReadWriteOnce PVCs, RollingUpdate deadlocks; you need Recreate strategy and a generous termination grace period
- Writing good issues forces a clarity that sprint planning rarely delivers; the forcing function alone is worth the setup cost
What Is Harness Engineering?
Before I explain what I built, I need to explain why the framing matters.
Birgitta Böckeler’s article for Martin Fowler defines harness engineering as building explicit controls around coding agents to increase the probability they succeed on the first attempt and self-correct before human review. The mental model is cybernetics: a governor that uses feedforward guides (preventing problems) and feedback sensors (catching problems post-generation) to keep the system on track.
Three regulation dimensions matter:
- Maintainability harness: linters, formatters, type checkers. Fast, cheap, deterministic.
- Architecture fitness harness: structural tests, module boundary checks, fitness functions.
- Behaviour harness: tests, mutation testing, LLM-as-judge review.
The cleanest formulation I have found: Agent = Model + Harness. The model provides the reasoning. The harness determines whether that reasoning produces something safe to ship.
A 2026 structural analysis of autonomous systems: Gemini Research found something counterintuitive: frequent AI tool users deploy more often but experience more deployment problems than their less-frequent peers. The researchers named it the AI Velocity Paradox. The bottleneck has shifted from code generation to verification and deployment. Generating faster without verifying better just means producing wrong things faster. Harness engineering is the answer to that: shift the feedback left, run linting and testing inside the agent loop before any human reviewer sees the output.
AI Jason’s “WTF is Harness Engineering” breaks this down well; it extends the idea into long-running multi-session agents and introduces the pattern of a legible environment that any new agent session can reconstruct state from.
Garry Tan (YC) takes this further with what he calls “thin harness, fat skills.” The winning architecture pushes intelligence up into markdown skill files (the “fat” layer with all the judgment and process), keeps the orchestration harness thin (around 200 lines of loop and tools, Maestro sits at ~300 with FastAPI and SSE wired in), and pushes trust-requiring deterministic work down into the application layer. When the model improves, every skill gets better automatically. The harness never changes.
This is exactly the pattern Symphony embodies. And it is exactly what I wanted to build for my team’s GitHub workflow.
Symphony: The Elixir Inspiration
OpenAI’s Symphony project is an agent orchestrator written in Elixir/OTP. It polls Linear for issues, creates isolated per-issue workspaces, launches Codex agents, and manages them until issues reach terminal states. The Erlang/BEAM architecture gives it supervision trees, hot code reloading, and fault-tolerance that is genuinely difficult to replicate in most other runtimes.
I was not going to rewrite it in Elixir. My team runs Python. Our entire toolchain is Python. Asking engineers to debug Elixir supervision trees when an agent gets stuck in a planning loop was not a trade-off I was willing to make.
I stripped it to five core ideas:
- A polling loop that claims work from an issue tracker
- Per-issue isolated workspaces
- A state machine driven by issue labels
- An instruction template rendered per-issue
- A retry and recovery mechanism for stalled agents
Everything else is implementation detail. Maestro v2 is those five ideas, in Python, pointed at GitHub instead of Linear.
Architecture: Thin Harness, Fat WORKFLOW
The architecture follows three layers:
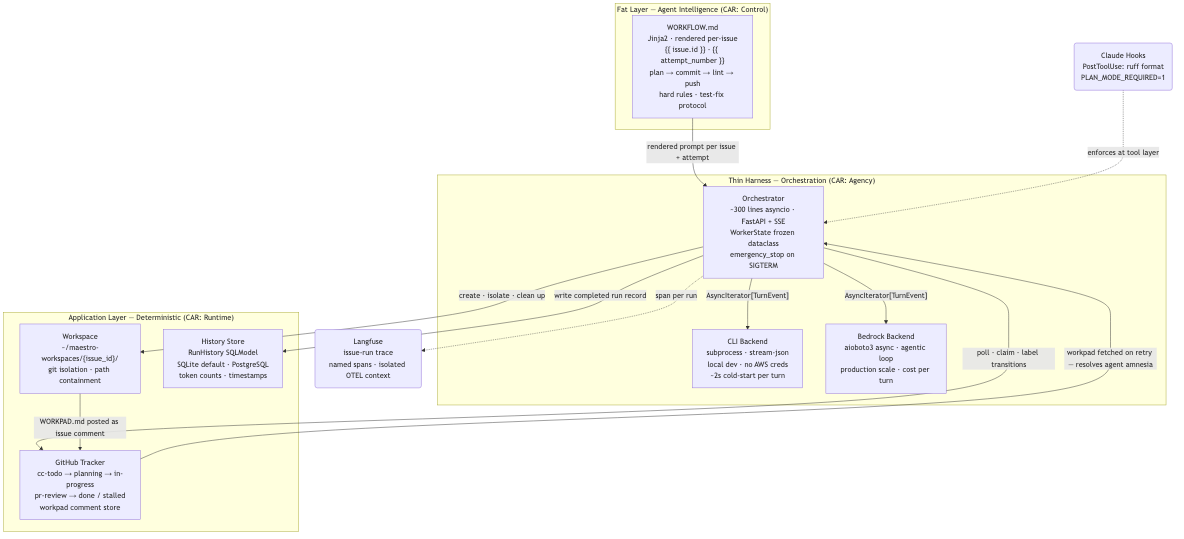
A useful frame for reading that diagram is CAR decomposition, a framework from a 2026 structural analysis of autonomous systems that formalises three pillars defining how an agent stays correct, acts in the world, and maintains state across sessions. Reading that analysis partway through the Maestro build clarified the runtime layer specifically: it named the workpad as a “progress file” and the history store as a “checkpoint” in a way that reframed what I had built as deliberate architecture rather than ad-hoc workarounds. The three Maestro layers map directly:
| CAR Pillar | What it governs | Maestro artifact |
|---|---|---|
| Control | Authority and policy |
WORKFLOW.md: hard rules, lint gate, test-fix protocol |
| Agency | Mediated tool surface | Isolated workspaces, bypassPermissions mode, path containment |
| Runtime | State and recovery | Workpad comments as progress files; history store as checkpoints |
The orchestrator is deliberately thin. It polls GitHub on a configurable interval, grabs issues labelled cc-todo, creates isolated workspaces under ~/maestro-workspaces/{issue_id}/, and dispatches an agentic workflow via Claude Code on a configured backend. The orchestrator does not know what a good implementation looks like. That is WORKFLOW.md’s job.
WORKFLOW.md is a Jinja2 template that gets rendered with the issue ID, title, description, and attempt number before each agent run. The rendered header gives the agent its context:
## Your Task
**Issue:** {{ issue.id }}: {{ issue.title }}
**Attempt:** {{ attempt_number }} of {{ max_attempts }}
{{ issue.description }}
The hard rules section reads exactly like this in production:
## Hard Rules (never break these)
1. **PLAN BEFORE CODE.** Do not write, edit, or delete a single file until you
have posted the workpad comment with acceptance criteria and plan.
This is non-negotiable.
2. **COMMIT AFTER EVERY FILE CHANGE.** After every Edit, Write, or Delete
operation: commit immediately. Do not wait for tests to pass or multiple
files to be changed. A single-file commit is correct.
*(rules 3–8 enforce workspace hygiene, branch naming, PR format; omitted for brevity)*
9. **LINT BEFORE PUSH.** Run the lint gate and confirm it exits 0 before
calling `Skill("push")` or `gh pr create`.
10. **TEST FIX PROTOCOL (non-negotiable).** Follow this exact sequence:
1. Run full suite once to collect all failures.
2. For each failure: run it alone -> fix it -> rerun alone to confirm -> commit.
3. Run full suite once at the end to confirm all green.
Dex Horthy’s “No Vibes Allowed” talk calls this pattern RPI: Research, Plan, Implement. The idea is that coding agents fail on complex codebases not because of model limitations but because poor context management collapses their context window mid-task. WORKFLOW.md is the structural answer: a fixed sequence that keeps the agent in the right phase at the right time.
When I catch an agent making mistakes I can prevent structurally, I fix WORKFLOW.md. The agent does not change. The harness does.
Writing good issues forces a clarity that sprint planning rarely delivers, and I did not expect that side effect. You slow down to think before you build, then let the harness build. You design the problem space and write the acceptance criteria. The agent handles execution. That forcing function alone is worth the setup cost.
The Label State Machine
The state machine uses GitHub labels directly:
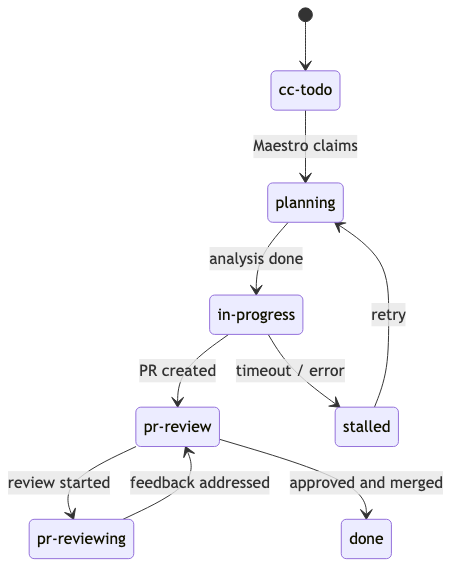
Maestro claims issues by reading the label state. No database coordination required between concurrent agents. GitHub is the lock.
What each label means and whose job it is to set it:
| Label | Set by | Meaning | Your action |
|---|---|---|---|
todo / cc-todo
|
You | New issue | Wait for workpad comment |
planning |
Maestro | Plan being written | Wait for workpad comment |
in-progress |
You / Maestro | Implementation underway | Wait for PR |
pr-review |
Maestro | PR open, awaiting review | Review the PR |
pr-reviewing |
Maestro | Addressing your feedback | Wait for fixes |
plan-revise |
You | Request plan revision | Leave a comment first, then set label |
stalled |
Maestro | Retries exhausted | Set in-progress to retry, closed to abandon |
done |
You | Issue complete | Nothing |
Two Backends, One Interface
The backend abstraction is the most important structural decision in the codebase. Both backends implement a single Protocol:
class AgentBackend(Protocol):
async def run_turn(
self,
prompt: str,
issue: Issue,
workspace_path: Path,
session_id: str | None,
) -> AsyncIterator[TurnEvent]: ...
async def stop_session(self, session_id: str) -> None: ...
CLI backend: spawns a subprocess, streams JSON turn events from the Claude CLI. Good for local development, no infrastructure, no AWS credentials required. The subprocess call looks like this:
cmd = [cli, "--permission-mode", "bypassPermissions",
"-p", prompt, "--output-format", "stream-json", "--verbose"]
proc = await asyncio.create_subprocess_exec(
*cmd, cwd=workspace_path,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
)
Bedrock backend: uses aioboto3 for async invocation, implements the full agentic loop with tool use handling. Good for production scale, which is exactly where the OOMKilled pod was running it.
(Three guesses which backend was running when exit code 137 arrived.)
The trade-offs are real and worth naming. The CLI backend adds roughly two seconds of subprocess cold-start overhead per turn, and its throughput ceiling is whatever the local Claude binary can handle; but it costs nothing beyond the API call and requires zero AWS credentials in development. The Bedrock backend eliminates the subprocess overhead and handles concurrent sessions cleanly at scale, but each agent turn is a direct API cost, and you need AWS credentials mounted in the pod. For most teams: CLI in development, Bedrock in production. The Protocol abstraction means you discover the production behaviour early by pointing CI at the Bedrock backend on merge, without touching orchestrator code.
Swapping backends is a single config value change. The orchestrator receives AsyncIterator[TurnEvent] regardless of which backend is running and never knows the difference.
The abstraction also makes adding backends cheap. I am currently replacing the Bedrock backend with the claude-code SDK directly. The subprocess plus JSON streaming loop works, but it feels like writing your own HTTP client when httpx already exists. The SDK gives proper async streaming without subprocess overhead, keeps the local-dev experience without requiring AWS credentials, and should make the agentic loop significantly thinner. The Protocol stays identical. The orchestrator will not notice.
Orchestrator State as Frozen Dataclasses
The orchestrator tracks every running issue as a WorkerState. Note what it is not: a mutable dict, a shared object, something you’d need to lock before touching.
@dataclass(frozen=True)
class WorkerState:
issue_id: str
issue: Issue
status: IssueStatus
attempt: int = 1
retry_at_ms: float = 0.0
input_tokens: int = 0
output_tokens: int = 0
session_id: str = ""
started_at_ms: float = field(default_factory=lambda: time.monotonic() * 1000)
Frozen dataclass. Immutable by construction. Every state mutation is a dataclasses.replace(worker, status=IssueStatus.RUNNING) call that produces a new object. The old one is discarded. The event loop owns the write path. API handlers get immutable OrchestratorSnapshot objects over SSE. No locks anywhere in the codebase. Frozen dataclasses. No locks. Correct by construction. It is what I should have shipped from day one.
17 Custom Skills
The thin harness principle extends to the tooling around Maestro itself. Rather than fat Makefile targets or ad-hoc scripts, the project ships with 17 Claude Code skills. Five representative ones:
-
/debug: triages stuck or failed runs by issue ID -
/workflow-lint: validatesWORKFLOW.mdJinja2 syntax before commits -
/fix-test: enforces the three-suite test-fix protocol -
/dashboard-health: post-deploy smoke test -
/agent-replay: reconstructs a session timeline from logs
These are not documentation. They are callable procedures that encode the team’s institutional knowledge about operating the system. Anyone picking up the project for the first time can run /debug 42 and get a structured diagnosis of what went wrong with issue 42, without reading 600 lines of orchestrator code.
Claude Hooks: Enforcement at the Tool Layer
WORKFLOW.md tells the agent what to do. Claude hooks make some of it happen regardless of what the agent decides.
The PostToolUse hook in settings.json fires on every Write or Edit call and auto-formats any modified Python file with ruff before the agent’s next turn:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "jq -r '.tool_input.file_path // empty' | { read -r f; case \"$f\" in *.py) (cd /backend && uv run ruff format --line-length 120 \"$f\");; esac; }",
"timeout": 30,
"statusMessage": "Formatting Python..."
}
]
}
]
}
}
The agent does not choose to format. The harness does it for the agent, on every file write, unconditionally. The instruction (“lint before push”) and the enforcement are different layers.
The Docker settings file goes further. CLAUDE_CODE_PLAN_MODE_REQUIRED=1 forces the agent into plan mode at the execution engine level. It cannot skip the planning phase even if the WORKFLOW.md instruction is misread or the context window is under pressure. skipDangerousModePermissionPrompt: true means the agent never stalls on permission dialogues inside the pod. The harness grants trust upfront; WORKFLOW.md constrains what the agent does with it.
This is the Control pillar from CAR decomposition applied below the prompt layer. The hook fires whether or not the agent remembered the rule.
Observability: Seeing Inside the Pod
Here is the problem with running Claude Code inside a Kubernetes pod: you have no shell access, no live REPL, and no insight into what the agent is deciding mid-turn. You have a container that is either producing a PR or not.
(Before I added Langfuse, debugging a stalled agent meant reading 2000 lines of container logs and guessing. After: I open the trace and see the agent spent 40 seconds in tracker.toctou_check because the issue label had been moved by a concurrent run. Three seconds to diagnose.)
Every issue run becomes a top-level Langfuse trace. Key operations are named spans:
_trace_ctx = langfuse.start_as_current_observation(
as_type="span",
name="issue-run",
input=issue.title[:500],
metadata={"issue_id": issue.id, "attempt": attempt},
)
with _trace_ctx as trace:
with _obs_span(langfuse, "tracker.toctou_check"):
... # re-validates issue is still claimable before workspace creation
with _obs_span(langfuse, "tracker.move_to_planning"):
... # label transition: cc-todo -> planning
asyncio.create_task() copies the current context at creation time, so each concurrent issue runner gets an isolated OTEL context. Spans from issue #42 do not bleed into issue #37’s trace even when both are running simultaneously.
When the run completes, the trace is updated with final status, token counts, session ID, and a redacted transcript. In Langfuse, you can see exactly where each run spent tokens, which spans took longest, and at what point a stalled run stopped producing output. The build_client factory returns None when observability is not configured, so the tracing wraps in contextlib.nullcontext() and the code path is identical with or without Langfuse:
def build_client(config: ObservabilityConfig):
if not config.is_active:
return None
try:
return Langfuse(
public_key=config.public_key,
secret_key=config.secret_key.get_secret_value(),
base_url=config.base_url,
)
except Exception as exc:
logger.warning("observability.init_failed, tracing disabled: %s", exc)
return None
The feedback sensor principle from harness engineering, applied to the orchestrator layer: you cannot improve what you cannot observe.
History Store
Every completed run (whether it ended in a merged PR, a stalled retry, or an error) gets written to the history store. The schema captures exactly what you need for post-mortems:
class RunHistory(SQLModel, table=True):
__tablename__ = "run_history"
id: str = Field(primary_key=True)
issue_id: str
title: str
final_status: str
attempt: int
input_tokens: int = Field(default=0)
output_tokens: int = Field(default=0)
session_id: str = Field(default="")
started_at_ms: float # monotonic; use for duration
completed_at_ms: float # monotonic; use for duration
transcript: str = Field(default="")
created_at: float # Unix epoch; use for display
SQLite is the default. No infrastructure, no migration tooling, no connection pool to manage. For most teams running Maestro on a single node, SQLite with WAL mode handles the write volume without complaint.
PostgreSQL becomes worth it when you need query performance across thousands of runs, or are running Maestro in a containerised environment where you cannot rely on a persistent local volume. Switching is a single environment variable: HISTORY_BACKEND=postgres with a HISTORY_POSTGRES_DSN pointing at your database.
The history API (GET /api/v1/history) supports filtering by issue ID, status, and date range, useful for answering “how many issues stalled last week?” or “what is the average time from claim to PR for these complexity 1 issues?”
Deployment
Maestro ships as a single Docker container. The multi-stage build produces a Python 3.13-slim image that runs nginx and uvicorn under supervisord. Nginx serves the React 19 frontend as static assets and reverse-proxies /api routes to the FastAPI backend. Everything is reachable on port 8080.
The following diagram shows how the service connects to its external dependencies at runtime:
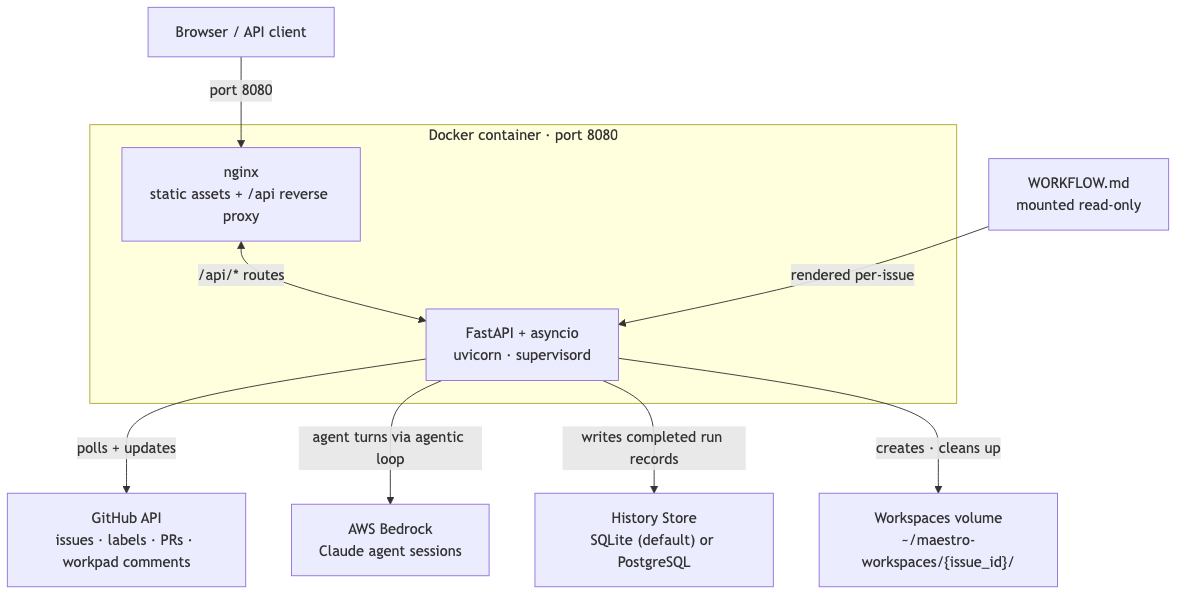
Locally, docker compose up mounts three volumes: WORKFLOW.md as read-only (so you can edit it without rebuilding), a named volume for workspaces (so they survive container restarts), and a named volume for logs.
In production, the container is deployed via ArgoCD with the image pushed to an internal JFrog registry on every merge to the main branch. The WORKFLOW.md is baked into the deployment as a ConfigMap, which means harness changes go through the same review process as code changes. Intentionally.
Taking the Hit in Dev
I had deployed the service to Kubernetes. The CI pipeline was green. The Docker build had passed. I was confident.
Then I pointed it at two real issues with real failing tests, and the pod died in five minutes.
The Kubernetes events log said everything: two Claude CLI subprocesses spawned simultaneously, each one carrying a 60k-token prompt payload, each one keeping stdout pipes open waiting for streaming JSON. The combined RSS blew past 512Mi. The OOM killer picked the pod as the highest-priority target. Restart backoff. CrashLoopBackOff. The ArgoCD dashboard went red.
The fix was three lines in the Helm values file:
resources:
limits:
cpu: 2
memory: 2Gi # was 512Mi
requests:
cpu: 200m
memory: 512Mi # was 256Mi
Four times the limit. For a “small internal tool”.
The memory fix exposed the next problem. After bumping resources, I ran the agents again. This time they ran long enough to start writing workspace files. Then I redeployed. The pod restarted. The workspaces were gone, because I had been mounting them inside the container’s ephemeral filesystem. Every in-progress run started over from scratch. The history was intact in SQLite, but the actual checkout directories, the partial commits, the WORKPAD.md files, all gone.
The solution was a persistent volume. EBS, ReadWriteOnce. 5Gi for workspace storage. But EBS ReadWriteOnce volumes create their own problem: RollingUpdate strategy deadlocks when a PVC is involved. The new pod cannot mount the volume until the old pod releases it, but the old pod does not terminate until the new pod is Ready. Both pods wait for each other indefinitely.
The Helm values comment I left myself explains the fix:
# Recreate required: EBS ReadWriteOnce PVCs cannot be mounted by two pods simultaneously.
# RollingUpdate would deadlock: new pod can't mount until old pod terminates,
# but old pod only terminates after new pod is Ready.
strategy:
type: Recreate
# Allow agent cleanup and Postgres history flush before SIGKILL.
# Default 30s is too short for in-flight agent session teardown.
terminationGracePeriodSeconds: 120
The terminationGracePeriodSeconds: 120 exists because the default 30 seconds is not enough time for an in-flight agent session to finish its current tool call, write its workpad, and flush its run record to PostgreSQL. Without it, mid-run agents get SIGKILL’d and the history record is either incomplete or missing. 120 seconds gives enough runway for graceful shutdown without hanging deploys indefinitely.
The graceful_shutdown handler in the orchestrator cancels all running tasks and waits for them to drain:
async def emergency_stop(self) -> dict:
"""Cancel all running agents immediately and pause new dispatches."""
self._paused = True
killed = list(self._workers.keys())
logger.warning("orchestrator.emergency_stop killing=%s", killed)
for iid, task in list(self._tasks.items()):
task.cancel()
self._tasks.clear()
for iid, ws in list(self._workers.items()):
self._fanout_sse({"type": "state_change", "issue_id": iid,
"from": ws.status, "to": "killed"})
asyncio.create_task(
self._post_stalled_comment(iid, ws.attempt, "Emergency stop triggered.")
)
self._workers.clear()
self._stopped_count += len(killed)
return {"killed": killed, "count": len(killed), "paused": True}
When SIGTERM arrives, this runs before SIGKILL. The in-progress workpad comments get posted. The history records get written. The next agent session that picks up the issue finds context instead of silence.
None of this is complicated. All of it required actually running the thing in production to discover.
Hard-Earned Lessons
1. Your Workflow Document Is a First-Class Artifact
I spent the first week treating WORKFLOW.md as configuration. It was not. It was the most important piece of code in the entire project.
Every repeated failure pattern I observed (agents writing code without planning, pushing without linting, forgetting to update tests) was a symptom of something WORKFLOW.md had not explicitly prohibited or structured. When I started treating it like a firmware specification and writing version-controlled changelog entries for every edit, the failure rate dropped measurably.
The feedforward guide principle from harness engineering applies directly: anticipate the failure mode, encode the prevention in the template. Do not wait for the feedback sensor to catch it.
The lesson: If the agent is misbehaving, the first place to look is the instruction template, not the model selection.
2. Asyncio-Only Is Non-Negotiable at Scale
I considered using ThreadPoolExecutor for agent dispatch. I needed to run up to 10 concurrent issues and each one required its own subprocess call to the Claude CLI. Threads felt natural.
Then I modelled what happens when 10 threads all try to read and write to shared orchestrator state at tick boundaries. Race conditions. Lock contention. Subtle ordering bugs that only reproduce under load. Three hours of debugging later, I scrapped the threads entirely.
The asyncio model gives one coroutine ownership of all state mutations. API handlers read via immutable OrchestratorSnapshot objects. The polling loop is a single async for that never blocks. The WorkerState frozen dataclass makes the intent explicit: mutating state is a replace-and-reassign operation, not an in-place update.
# State transition: produce a new WorkerState, discard the old one
self._workers[issue_id] = dataclasses.replace(
worker, status=IssueStatus.RUNNING, session_id=new_session_id
)
At 10 concurrent agents, there are no locks because there is no shared mutable state. The event loop enforces the invariant by construction.
The lesson: In an event-loop-first runtime, threading is not a performance optimisation. It is a correctness problem waiting to surface.
3. Per-Issue Isolation Prevents Cascade Failures
My first prototype ran agents in a shared workspace directory. An agent working on issue #42 could, and did, accidentally stage files from issue #37 that were checked out nearby. One git add . from the wrong directory polluted three other workspaces.
Isolated workspaces are not about agent paranoia. They are about failure blast radius. When issue #42 fails and I need to inspect what happened, I want a clean git history showing exactly what that agent did, without noise from other concurrent runs.
The workspace path containment check (Path.resolve() before dispatch) also prevents path traversal if a malformed issue description somehow injects a path into workspace creation. Paranoid? Yes. Worth it? Also yes. The actual creation code makes both guarantees explicit:
@classmethod
async def create(
cls, issue_id: str, workspace_root: Path, hooks: HooksConfig
) -> "Workspace":
safe_id = _safe_identifier(issue_id)
workspace_path = workspace_root / safe_id
_assert_contained(workspace_path, workspace_root) # raises on traversal
workspace_path.mkdir(parents=True, exist_ok=True)
ws = cls(path=workspace_path, issue_id=issue_id)
await _run_hook("after_create", hooks.after_create, workspace_path)
return ws
_assert_contained resolves both paths and raises if the workspace escapes the root. _safe_identifier strips anything that could turn an issue ID into a relative path component. Two lines. Both earned.
The lesson: Isolation is a correctness guarantee before it is a security guarantee. Design for it from day one.
4. Runtime Config Overrides Belong in the Harness, Not the Restart Script
Early on, when I wanted to test with a cheaper model or reduce concurrency during a noisy period, I had to restart the service and redeploy. The agent did not know about runtime configuration.
Adding a PATCH endpoint at /api/v1/config that accepts ephemeral overrides changed how I operate the system. I can drop concurrency from 10 to 2 during peak hours, switch models for a batch of test issues, and revert all changes on next restart, without touching a configuration file.
@router.patch("", response_model=ConfigSnapshot)
async def apply_overrides(
request: ApplyOverridesRequest,
app_context=Depends(get_app_context),
):
blocked = [k for k in request.overrides if k in BLOCKED_OVERRIDE_KEYS]
if blocked:
raise HTTPException(
status_code=422,
detail=f"Cannot override blocked keys: {', '.join(blocked)}",
)
app_context.runtime_config.apply_overrides(request.overrides)
if "server.log_level" in request.overrides:
_sync_log_level(request.overrides["server.log_level"])
return ConfigSnapshot(**app_context.runtime_config.snapshot())
Some keys are intentionally blocked: tracker.kind, workspace.root, server.port. These require a restart because changing them mid-run would orphan workspaces. The distinction between “can change at runtime” and “requires restart” is not arbitrary. It is a consequence of which state the system has already committed to.
The lesson: Separate the things that need a restart from the things that do not. Expose the latter as a first-class API.
5. The Workpad Comment Pattern Solves Agent Amnesia
A Claude agent session is stateless across turns. If Maestro retries a stalled issue, the new session starts cold. It has the issue description but no memory of what the previous session attempted, what failed, or what partial work exists in the workspace.
The solution was the workpad: a structured comment that Maestro posts on the issue after the first planning turn. Every agent session starts by reading the workpad. The workpad contains the analysis, acceptance criteria, approach decisions, and a running log of what each attempt did.
The agent writes its plan to WORKPAD.md before touching any files. On turn 1, Maestro reads it and posts it as a GitHub comment:
if turn == 1:
workpad = workspace.path / "WORKPAD.md"
if workpad.exists():
plan_text = workpad.read_text(encoding="utf-8")[:3000]
await tracker.create_comment(
issue.id,
f"📋 **Maestro plan**\n\n{plan_text}\n\n> _🏷 `{instance_id}`_",
)
What the posted comment actually looks like:
## Claude Workpad
hostname:path@git-sha
### Findings
Root cause, relevant files, current behaviour.
### Acceptance Criteria
- [ ] Specific, testable criteria for "done"
### Plan
- [ ] 1. Step one
- [ ] 1.1 Sub-step
- [x] 2. Completed step (checked off as work progresses)
### Files to Change
- `path/to/file.py` — what changes and why
### Notes
- Complexity score: 0.45 (non-trivial — awaiting approval)
Below 0.3, the agent proceeds automatically. At 0.3 or above, the label stays planning until a human sets in-progress. The score and the plan are in the same comment: the human approves what the agent will build and how complex it believes the task to be, in one place.
No vector store. No embedding API. No session memory. A markdown file on disk, posted to a GitHub comment thread. On retry, the WORKFLOW.md instructs the new agent to read the workpad comment before doing anything else. The harness provides the memory; the model reads it.
This is harness-level memory. Not model memory. Not session memory. A persistent, human-readable record attached to the work item itself.
Research on agentic architectures gives this pattern a name: solving the persistence mismatch. When the runtime environment is missing state the model was trained to expect, failure rates in complex multi-session tasks can reach 80%. The workpad is not clever engineering. It is the minimum viable solution to a known failure mode.
The lesson: Memory is a harness concern, not a model concern. Give the agent a place to write its state.
6. Production Surprises Are Specification Gaps
The OOMKilled pod, the lost workspaces on restart, the EBS PVC deadlock with RollingUpdate: none of these were bugs in the code. They were gaps in the specification of what “running at scale” actually meant.
The 512Mi memory limit felt reasonable when I was thinking about a FastAPI server. It was not reasonable when I was actually running two Claude CLI subprocesses simultaneously, each with a 60k-token context window, each streaming JSON back over stdout pipes. The resource model I had in my head did not match the resource model the runtime was enforcing.
The same pattern held for the PVC. I knew workspaces needed to persist across runs. I had not thought through what “across runs” meant when the pod itself restarts. Ephemeral filesystem and durable workspaces are not compatible requirements. The Kubernetes storage model forces you to make this explicit.
Every one of these surprises produced a Helm values comment explaining why the setting exists and what breaks if you change it back. Future-me, or anyone else who picks this up, will not have to rediscover these constraints by hitting a CrashLoopBackOff on a Saturday afternoon.
The lesson: Resource allocation is a specification, not a guess. Write it down and explain it at the point of configuration, not in a runbook nobody reads.
Trade-offs Worth Naming
No orchestration system comes free. Here are the ones I have actually hit, not the ones I anticipated.
It rewards well-scoped issues and punishes vague ones. WORKFLOW.md’s planning step helps, but the agent cannot synthesise acceptance criteria from “improve performance” or “clean this up.” Good issues become great agent runs. Ambiguous issues become expensive stalls that consume two attempts before routing back to cc-todo. The forcing function of writing a proper issue is real; it is also the ceiling of what the system can deliver.
Cost-per-run is non-trivial. On Bedrock, a multi-turn run through a complex issue with several failing tests costs real money. The token counts are in every Langfuse trace. I’ve been looking at them, wincing, and telling myself the engineer-hours saved justify it. I should measure that instead of assuming.
The harness amplifies the test suite you already have. If your tests are shallow, Maestro produces code that passes shallow tests. It does not fix a weak feedback sensor. A well-harnessed agent on a well-tested codebase is exceptional. The same harness on a poorly tested codebase produces merges faster with the same quality floor.
Recreate strategy means a brief downtime window on every deploy. The EBS PVC fix is correct for an internal tool. For anything customer-facing, you would need a different persistence strategy: a shared external database for workspace state, or stateless workspace creation on each run.
Conclusion
The winning skill is no longer “using AI” but orchestrating it through good harness design. Symphony showed me the pattern. The harness engineering literature gave me the vocabulary. Maestro v2 is what happens when you apply those ideas to a team’s actual GitHub backlog.
The most counterintuitive part of building it was realising how little of the intelligence lives in the orchestration code. The orchestrator is glorified polling with a state machine. The model provides the reasoning. The harness (WORKFLOW.md, isolated workspaces, workpad comments, linter gates) determines whether that reasoning produces something you can actually merge.
And that Saturday afternoon? The pod crashing at 512Mi was not a bug in the planning. It was the harness telling me exactly what it needed. I had under-specified the runtime. The Kubernetes events log said so clearly, immediately, and in a way I could not ignore. That is the feedback sensor principle working exactly as described: catch it before production, fix it in the spec, move on. I built this because I was tired of context-switching mid-thought. Mornings are for thinking now. Maestro handles the rest.
(Though I will admit: watching agents simultaneously work through a failing test backlog on a Saturday afternoon, knowing you will come back to PRs, is a specific kind of satisfaction that is hard to describe. Even if the first attempt took out the pod.)
If you have been putting off that idea sitting in the back of your head, maybe the best thing you can do for your productivity is close the laptop for a week.
References
- Harness Engineering for Coding Agent Users, Birgitta Böckeler for Martin Fowler: The foundational article defining feedforward guides, feedback sensors, and the three regulation dimensions
- OpenAI Symphony, Elixir Orchestrator: The Elixir/OTP agent orchestrator that inspired Maestro v2’s architecture
- OpenAI Harness Engineering Post: OpenAI’s companion post on harness engineering principles
- Thin Harness, Fat Skills, Garry Tan (@garrytan): The architecture pattern: push intelligence into fat skill files, keep the harness ~200 lines
- How I Built 20+ Custom AI Coding Skills to Automate My Entire Engineering Workflow: How the skill architecture that Maestro’s 17 project skills build on came together
- Did I Just Accidentally Build a Memory Management System for Claude Code?: The memory patterns that informed Maestro’s workpad design
- Running Google ADK Agents on AWS Bedrock via LiteLLM in Production: Multi-backend agent patterns that shaped Maestro’s backend abstraction
- WTF is Harness Engineering and Why It Matters, AI Jason: Practical breakdown of harness engineering for long-running multi-session agents: legible environments, verification loops, and the initialiser+coding-agent pattern
- No Vibes Allowed: Solving Hard Problems in Complex Codebases, Dex Horthy: The RPI (Research, Plan, Implement) framework: why coding agents fail on brownfield codebases and how structured context management fixes it
- The Structural Evolution of Autonomous Systems, Gemini Deep Research: The CAR decomposition framework (Control, Agency, Runtime) and the persistence mismatch research that gave direction on the workpad-as-progress-file and history-store-as-checkpoint architecture
- Langfuse: Open-source LLM observability used to trace agent runs inside the pod