
The Story

In this post, I will walk you through how I deployed a people counter application which will demonstrate how one would create a smart video IoT solution using Intel® hardware and software tools.
The app will detect people in a designated area, providing the number of people in the frame, average duration of people in frame, and total count.
Some other example potential use cases for this app are as follows:
- For security reasons, it could be used for industrial or residential purposes in order to detect any unauthorised persons.
- With the current COVID-19 pandemic, this app would help guarantee a place is not overcrowded, or there are some limitations related with the quantity of people allowed to be there.
- Retail stores could create people traffic heat-maps to check where people prefer to be in the store, providing useful information for targeted marketing, products positioning and even how many people visited the store.
- In emergency scenarios, it would be useful to know how many people are inside a place (building, factory, etc) as an indicator for possible rescue operations.
Note: The applications is not perfect and it might result in false-positives or true-negatives. For example, a person could enter with a blanket covering themselves and the app (as it is presented here) will not make a detection. It is possible to include other elements to avoid this situations, but as for today, there are not perfect people detection models.
TL; DR
Code can be found here: https://github.com/mmphego/people-counter-openvino-edgeai-project
How it Works
The app uses the Inference Engine included in the Intel® Distribution of OpenVINO™ Toolkit. The model used detects and identifies people in a video frame. The app counts the number of people in the current frame, the duration that a person is in the frame (time elapsed between entering and exiting a frame) and the total count of people. It then sends the data to a local web server using the Paho MQTT Python package.

The app can be used in different scenario. If high accuracy is required, then all factors including lighting, camera focal length, image size/resolution, position of camera and model accuracy contribute to output result.
Lighting should be reasonable to detected objects, It should not to dark so that model fail to detect objects. Camera position also matters for accuracy purposes. If object structure is clear from current camera position, model will easily able to detect. Image Size should not too small or too big, it should be according to model used. More pre-processing is required if it is far from required size. Most critical is model accuracy we are currently using. Model with high accuracy will provide more accurate inference
Project Pipeline
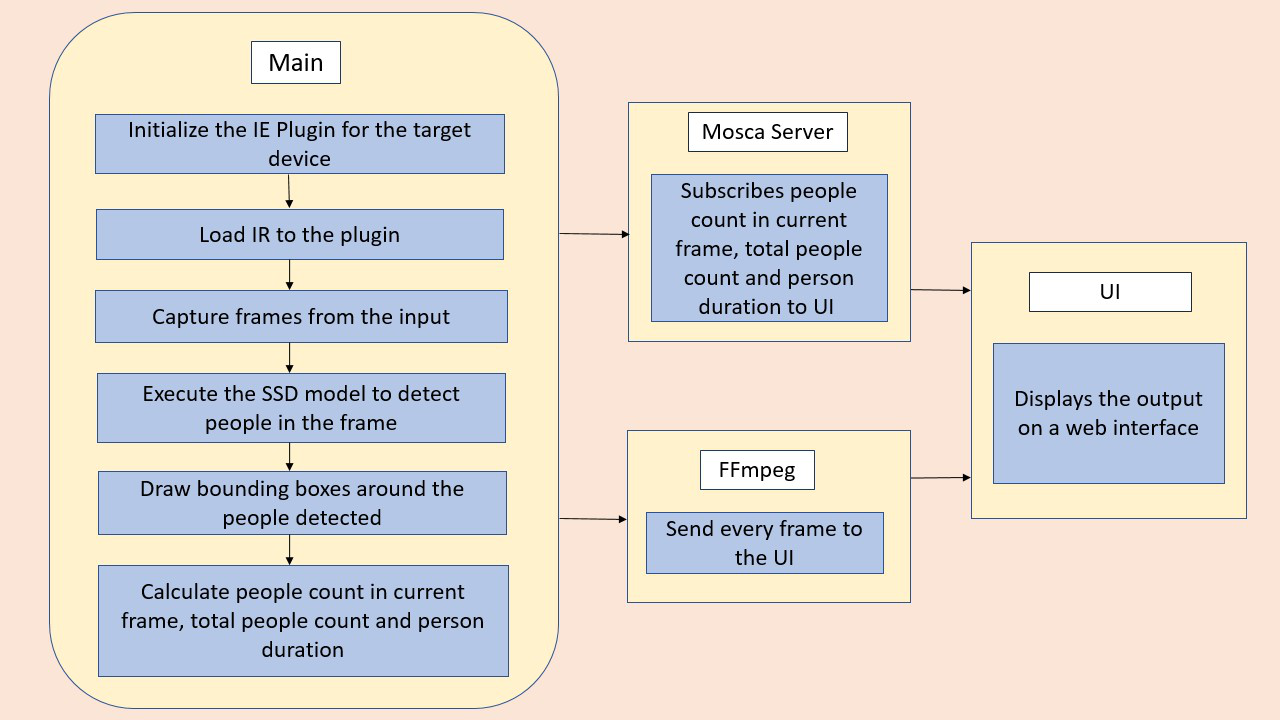
Minimum Requirements
Hardware
- 6th to 10th generation Intel® Core™ processor with Iris® Pro graphics or Intel® HD Graphics.
- OR use of Intel® Neural Compute Stick 2 (NCS2)
Software
- Intel® Distribution of OpenVINO™ toolkit 2019 R3 release
- Node v6.17.1
- Npm v3.10.10
- CMake
- MQTT Mosca server
Setup
Install Intel® Distribution of OpenVINO™ toolkit
Refer to the relevant instructions for your operating system for this step.
Install Nodejs and its dependencies
Refer to the relevant instructions for your operating system for this step.
Install npm
There are three components that need to be running in separate terminals for this application to work:
- MQTT Mosca server
- Node.js* Web server
- FFmpeg server
From the main directory:
- For MQTT/Mosca server:
cd webservice/server
npm install
- For Web server:
cd ../ui
npm install
Note: If any configuration errors occur in mosca server or Web server while using npm install, use the below commands:
sudo npm install npm -g
rm -rf node_modules
npm cache clean
npm config set registry "http://registry.npmjs.org"
npm install
What model to use
Some of the models evaluated before opting for the one used for this project:
| Model Name | Model Size [Post Conversion] (MB) | Average Precision (AP) (%) | Inference Ave. Time (ms) | N. People Detected | Completion Time (s) | Running Project |
|---|---|---|---|---|---|---|
| person-detection-retail-0002 | 6.19 | 80.14 | 47.684 | 0 | 73.40 |  |
| person-detection-retail-0013 | 1.38 | 88.62 | 14.358 | 11 | 28.63 |  |
| ssd_mobilenet_v2_coco | 64.16 | 21.949 | 30 | 38.17 |  |
|
| ssdlite_mobilenet_v2_coco | 17.07 | 11.791 | 40 | 25.97 |  |
|
| pedestrian-detection-adas-0002 | 2.22 | 88 | 14.435 | 71 | 27.36 |  |
After careful consideration, the selected model for the project was one of the Intel® Pre-Trained Model *person-detection-retail-0013* considering the size of the model, number of detected people and average inference time.
Downloading The Model
An example as to how to download a model from the Open Model Zoo and convert to Intermediate Representations. Alternatively download TensorFlow Object Detection Model from the Model Zoo which contains many pre-trained models. For this project, various classes of models were tested from the Open Model Zoo and TensorFlow Model Zoo.
Typical Usage:
- Download the correct model for object detection using the docker container from the Open Model Zoo.
docker run --rm -ti -v "$PWD":/app mmphego/intel-openvino\
/opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/downloader.py \
--name ssd_mobilenet_v2_coco \
--precision FP16
- Convert TensorFlow model to Intermediate Representation.
cd public/ssd_mobilenet_v2_coco/ssd_mobilenet_v2_coco_2018_03_29
docker run --rm -ti -v "$PWD":/app mmphego/intel-openvino \
/opt/intel/openvino/deployment_tools/model_optimizer/mo.py \
--input_model frozen_inference_graph.pb \
--tensorflow_object_detection_api_pipeline_config pipeline.config \
--reverse_input_channels \
--transformations_config /opt/intel/openvino/deployment_tools/model_optimizer/extensions/front/tf/ssd_v2_support.json
mv frozen_inference_graph.xml ssd_mobilenet_v2_coco.xml
mv frozen_inference_graph.bin ssd_mobilenet_v2_coco.bin
rsync -truv --remove-source-files ssd_mobilenet_v2_coco.{bin,xml} ../../../models/
Run the application
Note: In order to run the app locally export the 2 envvars (See: #a-note-on-running-locally)
export CAMERA_FEED_SERVER="http://localhost:3004"
export MQTT_SERVER="ws://localhost:3002"
Option 1
In order to run the application execute the following script:
bash runme.sh
This script with start the mosca server, ffserver, webui and app in the background - assuming that the install NPM step was followed.
Option 2
From the main directory:
Step 1 - Start the Mosca server
Docker Container
- Create a network bridge to communicate between the containers.
docker network create -d bridge openvino
- Build the docker container for the mosca-server.
docker build -t mmphego/mosca-server -f Dockerfile-mosca-server .
- Run the container while exposing port 3001 and 3002.
docker run \
-p 3002:3002 \
-p 3001:3001 \
--network="openvino" \
--name "mosca-server" \
-ti mmphego/mosca-server
You should see the following message, if successful:
Mosca server started.
Local Development
cd webservice/server/node-server
node ./server.js
You should see the following message, if successful:
Mosca server started.
Step 2 - Start the GUI
Docker Container
- Build the docker container for the Web UI
docker build -t mmphego/webui -f Dockerfile-ui .
- Run the container while exposing port 3000.
docker run \
-p 3000:3000 \
--network="openvino" \
--name "webui" \
-ti mmphego/webui
You should see the following log output:
> intel-people-counter-app@0.1.0 dev /app/webservice/ui
> cross-env NODE_ENV=development webpack-dev-server --history-api-fallback --watch --hot --inline
Project is running at http://0.0.0.0:3000/
webpack: Compiled successfully.
Local Development
Open new terminal and run below commands.
cd webservice/ui
npm run dev
You should see the following message in the terminal.
webpack: Compiled successfully
Step 3 - FFmpeg Server
Docker Container
docker run \
-p 3004:3004 \
--network="openvino" \
--name "ffmpeg-server" \
-ti mmphego/ffmpeg-server
You should see the following output:
Sat May 23 05:51:10 2020 FFserver started.
Local Development
Open new terminal and run the below commands.
wget https://github.com/vot/ffbinaries-prebuilt/releases/download/v3.4/ffserver-3.4-linux-64.zip
sudo unzip ffserver-3.4-linux-64.zip /usr/local/bin
sudo ffserver -f ./ffmpeg/server.conf
Step 4 - Run the code
Open a new terminal to run the code.
Setup the environment
You must configure the environment to use the Intel® Distribution of OpenVINO™ toolkit one time per session by running the following command:
source /opt/intel/openvino/bin/setupvars.sh -pyver 3.5
You should also be able to run the application with Python 3.6, although newer versions of Python will not work with the app.
Running on the CPU
When running Intel® Distribution of OpenVINO™ toolkit Python applications on the CPU, the CPU extension library is required. This can be found at:
/opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/
Depending on whether you are using Linux or Mac, the filename will be either libcpu_extension_sse4.so or libcpu_extension.dylib, respectively. (The Linux filename may be different if you are using a AVX architecture)
Though by default application runs on CPU, this can also be explicitly specified by -d CPU command-line argument:
python main.py \
-i resources/Pedestrian_Detect_2_1_1.mp4 \
-m your-model.xml \
-l /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/libcpu_extension_sse4.so \
-d CPU \
-pt 0.6 | ffmpeg \
-v warning \
-f rawvideo \
-pixel_format bgr24 \
-video_size 768x432 \
-framerate 24 \
-i - http://0.0.0.0:3004/fac.ffm
If you are in the classroom workspace, use the “Open App” button to view the output. If working locally, to see the output on a web based interface, open the link http://0.0.0.0:3004 in a browser.
Debugging with Docker
In order to see what is going inside the docker we need to sync the displays with --env DISPLAY=$DISPLAY --volume="/tmp/.X11-unix:/tmp/.X11-unix:rw".
docker build -t "$USER/$(basename $PWD)" .
xhost +
docker run --rm -ti \
--volume "$PWD":/app \
--env DISPLAY=$DISPLAY \
--volume="/tmp/.X11-unix:/tmp/.X11-unix:rw" \
"$USER/$(basename $PWD)" \
bash -c "source /opt/intel/openvino/bin/setupvars.sh &&python main.py -i resources/Pedestrian_Detect_2_1_1.mp4 -m models/ssd_mobilenet_v2_coco.xml"
xhost -
Running on the Intel® Neural Compute Stick
To run on the Intel® Neural Compute Stick, use the -d MYRIAD command-line argument:
python3.5 main.py \
-d MYRIAD \
-i resources/Pedestrian_Detect_2_1_1.mp4 \
-m your-model.xml \
-pt 0.6 | ffmpeg \
-v warning \
-f rawvideo \
-pixel_format bgr24 \
-video_size 768x432 \
-framerate 24 \
-i - http://0.0.0.0:3004/fac.ffm
To see the output on a web based interface, open the link http://0.0.0.0:3004 in a browser.
Note: The Intel® Neural Compute Stick can only run FP16 models at this time. The model that is passed to the application, through the -m <path_to_model> command-line argument, must be of data type FP16.
Using a camera stream instead of a video file
To get the input video from the camera, use the -i CAM command-line argument. Specify the resolution of the camera using the -video_size command line argument.
For example:
python main.py \
-i CAM \
-m your-model.xml \
-l /opt/intel/openvino/deployment_tools/inference_engine/lib/intel64/libcpu_extension_sse4.so \
-d CPU \
-pt 0.6 | ffmpeg \
-v warning \
-f rawvideo \
-pixel_format bgr24 \
-video_size 768x432 \
-framerate 24 \
-i - http://0.0.0.0:3004/fac.ffm
To see the output on a web based interface, open the link http://0.0.0.0:3004 in a browser.
Note:
User has to give -video_size command line argument according to the input as it is used to specify the resolution of the video or image file.
A Note on Running Locally
The servers herein are configured to utilize the Udacity classroom workspace. As such, to run on your local machine, you will need to change the below file:
webservice/ui/src/constants/constants.js
The CAMERA_FEED_SERVER and MQTT_SERVER both use the workspace configuration.
You can change each of these as follows:
export CAMERA_FEED_SERVER="http://localhost:3004"
export MQTT_SERVER="ws://localhost:3002"
Future Work
- Dockerize the application (hint: docker-compose)
- Benchmark application on various devices.
- Run VTune profiling software to find any bottlenecks.
- Instead of ffmpeg, research GStreamer usecase.